

Constat : la verticalisation du compute change la donne pour les producteurs de contenu
La frontière entre matériel, logiciel et services cloud se rétrécit : des acteurs historiques et nouveaux conçoivent des puces et des accélérateurs ad hoc pour l’IA, pendant que les régulateurs européens placent la souveraineté des semiconducteurs et l’empreinte énergétique des datacenters au cœur de leur agenda. Pour une agence web ou une équipe WordPress qui externalise de l’IA (génération de contenu, assistants, modération, embeddings), cela signifie que la performance, le prix et la localisation d’exécution ne sont plus neutres : ils varient selon le matériel et la stack du fournisseur, et peuvent entraîner un verrouillage commercial et technique. Cet article transforme ces signaux en décisions opérationnelles : quels risques vérifier, quelles clauses négocier, comment tester et piloter un basculement multi-cloud/hybride, et quelles priorités mettre en place pour protéger vos flux de production de contenu sans bloquer l’innovation.
Conseil pratique
Trois actions simples pour vérifier en une semaine si vos workflows sont dépendants d’un fournisseur ou d’un accélérateur.
- Exécutez votre modèle principal sur une VM CPU générique pour obtenir latence et précision de référence.
- Répétez la charge sur un accélérateur alternatif et comparez latence, débit et coût par requête.
- Exportez le modèle (poids) et restaurez‑le localement pour vérifier la portabilité et la complétude des exports.
Risques concrets et vérifications indispensables pour agences et équipes WordPress
Verrouillage fournisseur et portabilité des modèles
Les puces et stacks propriétaires peuvent rendre difficile le déplacement d’un modèle ou d’un workflow vers un autre provider. Vérifiez dans vos contrats la possibilité d’exporter les modèles et les poids, et la compatibilité des runtimes. Demandez explicitement le support de formats et d’outils ouverts (par exemple ONNX ou runtimes CPU génériques) et des engagements écrits sur l’exportabilité. Exigez une période de transition contractuelle et une assistance technique pour transférer modèles et données en cas de fin d’offre.
Localisation des données et conformité
Si des instances s’exécutent hors de la juridiction attendue, cela crée un risque réglementaire et réputationnel. Contrôlez l’emplacement physique des instances et des stockages, identifiez les sous-traitants « en cascade » et demandez la traçabilité des routes de stockage. Obtenez la possibilité de forcer la localisation d’exécution quand c’est critique et réclamez des logs d’audit démontrant où les données et modèles ont été traités.
Coûts réels : compute + énergie + transferts
Le prix affiché d’une instance peut masquer des coûts liés à l’énergie, à la variabilité des accélérateurs et aux transferts nationaux ou internationaux. Mesurez le coût total de possession (TCO) par workload : coût horaire de l’instance multiplié par la consommation moyenne, plus les frais de transfert et les éventuels suppléments énergétiques. Intégrez ces éléments dans vos comparatifs pour éviter les surprises lorsque vous basculez de test à production.
Compatibilité logicielle et maturité des accélérateurs
Des incompatibilités de frameworks, de versions logicielles ou d’optimisations propriétaires peuvent bloquer des déploiements. Demandez des matrices de compatibilité (frameworks, versions CUDA/ROCm si pertinentes, runtime), un accès à un environnement d’essai et des garanties de support pour PyTorch, TensorFlow et runtimes CPU. Vérifiez aussi la documentation et les procédures de montée en charge sur les accélérateurs proposés.
SLA, disponibilité et support
Pour des usages de production (site, chatbots, génération en batch), négociez des indicateurs mesurables : latence d’inférence, disponibilité, délai de résolution d’incident. Demandez des SLA avec pénalités claires et un plan d’évacuation des modèles si l’offre est interrompue. Exigez des processus documentés pour la reprise d’activité et la restitution des données et modèles exportables.
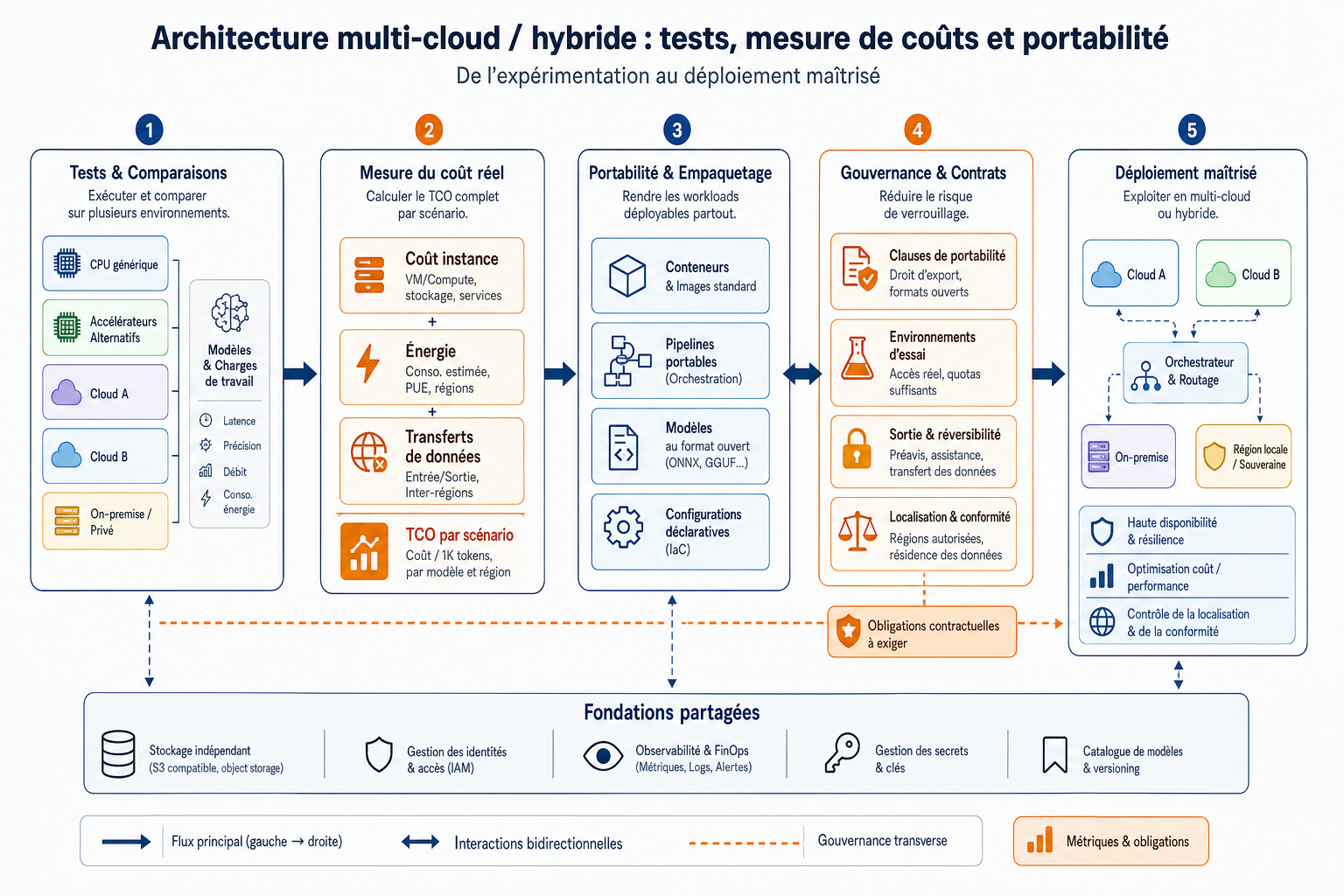
Priorités immédiates : actions à lancer cette semaine
Vérifiez et documentez l’emplacement des instances et du stockage pour chaque fournisseur utilisé, et demandez une attestation écrite si la localisation est critique. Relisez vos contrats pour la présence explicite de clauses d’exportation et de portabilité des modèles et des données, ou activez une remontée commerciale pour obtenir ces garanties. Lancez des tests rapides : exécutez vos modèles principaux sur une instance CPU générique et sur au moins un accélérateur alternatif pour mesurer latence et coût par requête. Calculez un TCO simple par workload (coût instance + estimation énergétique + transferts) afin de comparer les offres concurrentes. Activez des sauvegardes automatiques hors du fournisseur principal et validez que vous pouvez restaurer un modèle et ses poids localement. Enfin, établissez un plan de communication interne listant les responsables techniques et commerciaux, les preuves à fournir (logs, factures, preuves d’exécution) et une checklist de sortie pour chaque fournisseur afin d’éviter les surprises en cas d’arrêt ou de changement d’offre.
Stratégie d’achat et organisation opérationnelle pour rester agile
Négocier des clauses contractuelles pratiques
Priorisez des clauses de portabilité : export des modèles, accès aux poids et engagement sur la localisation d’exécution. Demandez des droits de retrait des données et des engagements sur les périodes de transition. Exigez l’accès à des environnements d’essai, des rapports d’utilisation détaillés et une définition claire des processus de sortie (formats standards, délais, assistance technique). Intégrez ces clauses dans le cycle d’achat avant de déployer en production.
Architecture cible : multi-cloud/hybride pragmatique
Déployez une architecture qui réserve des chemins de repli : gardez la possibilité d’exécuter les charges critiques sur des VM/CPU standard, et utilisez les accélérateurs propriétaires pour les tests ou les opérations de burst. Séparez le stockage (object storage indépendant) du compute pour faciliter la migration des données et des modèles. Préparez un pipeline CI/CD pour modèles capable de construire et déployer vers plusieurs cibles via des outils d’abstraction afin de réduire le temps de basculement.
Processus de validation et benchmarks
Définissez un protocole de test reproductible : jeux de données réduits, métriques claires (latence, throughput, coût par unité, précision). Exécutez ces tests sur CPU générique et sur au moins deux types d’accélérateurs pour chiffrer réellement les gains et les risques. Intégrez ces résultats au comité d’achat pour orienter les négociations tarifaires et les décisions de dépendance technique.
Gouvernance des modèles et responsabilités
Attribuez des rôles clairs : responsable achat pour les contrats, responsable infra pour ports et backups, responsable modèle pour tests et compatibilité, responsable conformité pour localisation et données. Documentez les décisions techniques et commerciales pour faciliter audits et arbitrages ultérieurs. Formalisez aussi les procédures d’escalade en cas de désaccord avec un fournisseur.
Budgétisation et pilotage du TCO énergétique
Incluez l’impact énergétique et les coûts de transfert dans les budgets projet. Mesurez la consommation effective sur des runs représentatifs et réévaluez périodiquement ces mesures. Utilisez ces relevés pour renégocier des tarifs, orienter vos choix vers des fournisseurs plus efficients localement, ou pour décider d’exécutions alternatives en période de forte demande.
Plan de migration progressive
Évitez les migrations « big bang ». Priorisez la portabilité des composants statiques (embeddings, petits modèles), testez la migration des services non critiques, puis planifiez le basculement des charges critiques avec fenêtres de validation et rollback défini. Préparez des backups hors fournisseur et des scripts d’export automatisés pour réduire le délai et le risque lors d’un départ ou d’un changement d’offre.
Conclusion : trois priorités concrètes à exécuter dès maintenant
Ces mesures visent à transformer une contrainte industrielle en avantage opérationnel sans bloquer l’innovation : obtenir des garanties contractuelles, mesurer les écarts réels de performance et disposer d’une architecture qui facilite le basculement.
- Obtenir et archiver l’emplacement d’exécution et les clauses de portabilité pour chaque offre IA utilisée.
- Lancer des tests comparés (CPU générique vs accélérateurs) sur vos workflows critiques pour mesurer latence, précision et TCO réel.
- Mettre en place une architecture et des contrats permettant un basculement progressif (stockage indépendant, exports standard, SLA clairs).
Points clés à retenir
- La verticalisation du compute rend la performance, le prix et la localisation d’exécution dépendants du matériel et de la stack du fournisseur, augmentant le risque de verrouillage.
- Mesurer le coût réel (instance + énergie + transferts) et tester les modèles sur CPU générique et sur accélérateurs alternatifs permet d’évaluer latence, précision et TCO avant passage en production.
- Négocier des clauses de portabilité, exiger des environnements d’essai et architecturer en multi‑cloud/hybride (stockage indépendant, pipelines déployables) réduit les risques opérationnels.
Foire Aux Questions
Comment vérifier que je peux vraiment déplacer un modèle vers un autre provider ?
Demandez contractuellement la possibilité d’exporter les modèles et les poids, le format d’export supporté et l’assistance technique pour la période de transition. Testez un export et une restauration locale avant toute mise en production.
Quels éléments inclure dans le calcul du coût réel (TCO) d’un workload IA ?
Au-delà du tarif horaire, intégrez la consommation énergétique observée sur des runs représentatifs, les frais de transfert et les éventuels suppléments liés aux accélérateurs. Mesurez sur charges réelles pour éviter les écarts test→prod.
Que demander dans les SLA pour les usages de production ?
Négociez des indicateurs mesurables (latence d’inférence, disponibilité), des délais de résolution d’incident, des pénalités claires et un plan d’évacuation des modèles avec restitution des données exportables.
Comment tester la compatibilité logicielle des accélérateurs ?
Exigez matrices de compatibilité (frameworks et versions), accès à un environnement d’essai et garanties de support pour vos frameworks (par exemple PyTorch/TensorFlow) ainsi que pour les runtimes CPU.
Faut‑il viser une migration complète ou progressive ?
Préférez une migration progressive : portabilité des composants statiques d’abord, tests sur services non critiques, puis basculement des charges critiques avec fenêtres de validation et rollback défini.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Acteur majeur du web et de la recherche, souvent source des evolutions SEO et IA.
OpenAI
Site officielEntreprise a l origine de modeles generatifs utilises pour redaction, code et assistants IA.
Sources et Références
- Qualcomm entre dans la bataille des centres de données avec le CPU Dragonfly C1000 et ses accélérateurs IA
- OpenAI entame son divorce avec Nvidia en annonçant ses premières puces faites maison
- AWS Graviton / Trainium / Inferentia - pages produits officielles
- TPU (Tensor Processing Unit) - Google Cloud
- Chips Act - site de la Commission européenne (initiative pour la production et la résilience des semiconducteurs en Europe)
Pourquoi cet article
Angle précis et actionnable - Le panorama des 48 dernières heures montre plusieurs signaux convergents : Qualcomm entre sur les CPU pour centres de données (Dragonfly C1000), OpenAI annonce ses propres puces, Oracle se recentre massivement sur l'IA et...








