

Hébergement WordPress « prêt IA » en 2026 : l’urgence concrète pour les agences et DSI
Pour une agence ou une DSI, l’hébergement WordPress n’est plus seulement une question de PHP, de sauvegardes et de montée en charge : il devient la façade d’applications qui sollicitent des services d’IA en production (chatbots internes, assistants métiers, recherche sémantique, génération de contenu). Plusieurs signaux récents - déploiements de ChatGPT Enterprise par des groupes tels que Samsung, annonces d’acteurs européens souhaitant proposer des LLM, et incidents publics ou restrictions nationales liés aux chatbots - rendent ce choix d’hébergement urgent. « Prêt IA » signifie au minimum accès maîtrisé à des GPU ou à des API LLM avec garanties contractuelles, contrôle de la résidence et du chiffrement des données, garanties de latence et de disponibilité pour l’inférence temps réel, et compatibilité avec l’écosystème WordPress (plugins, modes headless). Cet article détaille les critères opérationnels et une méthode pratique pour choisir une offre d’hébergement qui tient compte de ces contraintes.
Conseil pratique
Un petit pilote permet de valider intégration, latence et protections sans engager une migration complète.
- Cartographiez un flux métier simple et identifiez les données sensibles à anonymiser.
- Déployez un site de test WordPress en environnement isolé, ajoutez un proxy pour appels LLM externes et activez le chiffrement des transferts.
- Mesurez la latence end‑to‑end, contrôlez les logs et simulez une coupure d’API pour vérifier basculement et autoscaling.
Critères techniques et juridiques à exiger d’un hébergeur
Accès à l’infrastructure IA
Demandez clairement la disponibilité d’instances GPU ou de serveurs bare‑metal pour l’inférence privée et l’entraînement léger. Vérifiez les types d’instances proposés, les régions disponibles et la documentation technique sur les limites d’usage et l’autoscaling. Les offres GPU publiques (par exemple mentionnées par des acteurs européens et hyperscalers) doivent être accompagnées de SLA techniques détaillés pour ces ressources.
Connexions sécurisées aux API LLM externes
Exigez le support de connexions sortantes sécurisées : mutual TLS, IP allowlists, gestion centralisée et rotative des clés API, et possibilité d’utiliser des proxys privés ou des VPC endpoints. Demandez des engagements explicites sur l’absence de logs applicatifs non chiffrés chez l’hébergeur. Les entreprises qui adoptent des offres enterprise de fournisseurs externes réclament ces protections pour éviter la fuite de prompts et de données sensibles.
Souveraineté, résidence et conformité
Spécifiez la localisation des données (résidence) et les garanties de chiffrement au repos et en transit. Obtenez des engagements contractuels sur les sous‑traitants et les transferts internationaux de données. Les initiatives visant à proposer des LLM locaux renforcent l’argument d’un hébergement onshore lorsque la réglementation ou la politique interne l’exige.
Sécurité des intégrations et minimisation des données
Vérifiez la capacité de confinement des traitements (réseaux privés, sandboxing des workers, isolation des conteneurs), la qualité des traces d’audit et les options de prétraitement serveur (filtrage, anonymisation) avant tout envoi vers un LLM externe. Ces mesures réduisent le risque d’exfiltration et facilitent les investigations en cas d’incident.
Performance, latence et SLO pour l’inférence
Demandez des objectifs mesurables sur la latence et la disponibilité pour les appels d’inférence critiques. La latence end‑to‑end (client → WordPress → modèle) dépend fortement de la proximité des GPU ou de la qualité de l’API externe ; exigez des SLOs techniques et des outils de mesure pour suivre ces indicateurs en condition réelle.
Compatibilité WordPress et gestion des plugins
Contrôlez la capacité de l’hébergeur à supporter les exigences d’intégration WordPress : installation de conteneurs, accès SSH contrôlé, gestion des workers PHP sans impact sur les traitements ML asynchrones, et politiques de sauvegarde/restauration prenant en compte les caches sémantiques ou les données d’entraînement. Demandez des preuves de compatibilité avec les plugins et architectures headless ciblés.
Coûts, modèles contractuels et risques
Évaluez les coûts fixes versus la facturation à la consommation GPU, le coût des transferts de données et les clauses de responsabilité en cas de fuite. Privilégiez des contrats qui permettent de prouver la tenue des engagements : accès aux logs, droit d’audit et certifications ou attestations techniques.
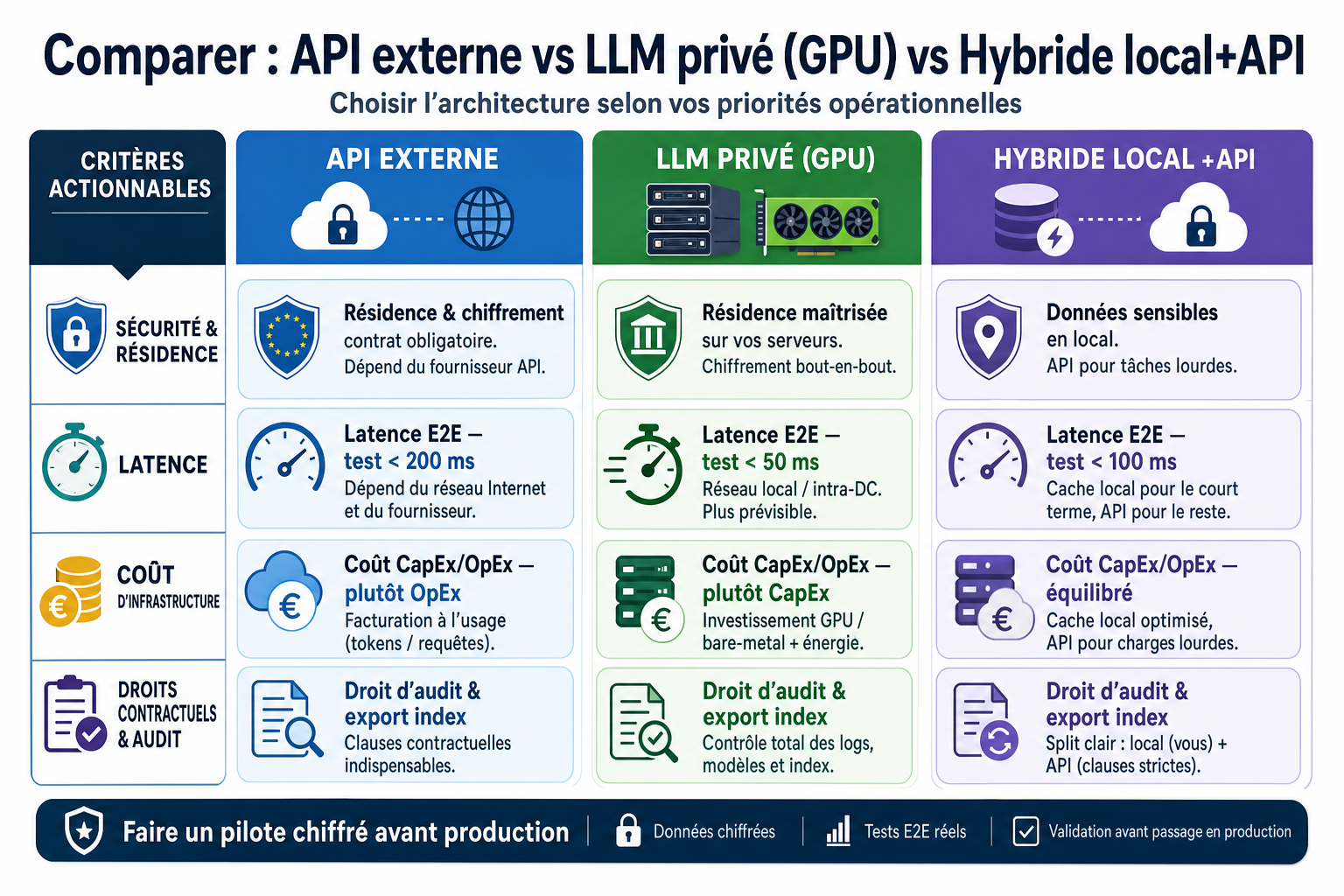
Les architectures possibles : micro‑choix qui déterminent le risque et le coût
Trois approches coexistent et orientent directement le risque et le budget : l’usage d’API LLM externes (faible charge opérationnelle mais dépendance fournisseur, latence et contrôle limités), l’hébergement d’un LLM privé sur GPU/bare‑metal (meilleure souveraineté et contrôle des données, coûts et opérations élevés), et l’architecture hybride (caches sémantiques et modèles légers en local, API externes pour les tâches lourdes). Le choix dépend du niveau de confidentialité des données, des exigences de latence et du budget : les APIs conviennent aux usages non sensibles et rapides à déployer, un LLM privé est recommandé pour des données régulées ou des exigences de résidence, et l’hybride offre une voie médiane qui limite les transferts tout en conservant l’accès à la puissance d’un hypercloud.
Plan d’action opérationnel pour choisir et déployer un hébergement prêt IA
Audit initial et critères de décision
Cartographiez les flux de données : quelles données transitent, leur sensibilité et leur origine. Définissez les cas d’usage LLM (temps réel versus batch) et les contraintes réglementaires sectorielles. Priorisez selon le risque métier : confidentialité élevée → LLM privé/onshore ; latence critique → GPU en proximité ou API à faible latence.
Scénarios d’architecture recommandés
- Starter : WordPress standard + API LLM via proxy privé, prétraitement et anonymisation côté serveur. Convient pour prototypes et cas non sensibles.
- Industriel : WordPress headless, cache sémantique interne, GPU distant accessible via VPC ou peering, pipelines de sauvegarde des index sémantiques.
- Critique : LLM privé sur bare‑metal en data center national, pipelines d’anonymisation avant inférence, audits et droit d’accès aux logs pour vérification réglementaire.
Pour chaque scénario, identifiez les exigences réseau (VPC, peering, endpoints privés), le stockage (chiffrement des caches, rétention des logs) et les règles de sauvegarde/restauration (inclure les index et métadonnées sémantiques dans les politiques de reprise).
Tests techniques et indicateurs à valider
Avant production, mesurez la latence end‑to‑end et le coût par requête, évaluez le taux d’erreur d’inférence et la couverture des logs d’audit. Simulez des montées en charge et des incidents (perte d’accès à l’API, montée brutale du trafic) pour vérifier l’autoscaling, les temps de basculement et les procédures de mitigation.
Clauses contractuelles et preuves exigibles
Incluez dans le contrat des SLA chiffrés pour latence et disponibilité, des engagements sur la résidence des données, un droit d’audit et des obligations de notification en cas de faille. Prévoyez des clauses de sortie qui couvrent l’export des modèles, des logs et des index sémantiques pour faciliter une migration future.
Mise en œuvre côté WordPress et intégration plugins
Organisez des environnements séparés (dev/stage/prod), mettez en place une gestion centralisée des clés et des secrets, et testez l’impact des plugins IA sur l’indexation et les caches. Définissez une politique de purge des données sensibles et conduisez une phase pilote chiffrée sur un flux métier ciblé avant tout déploiement global.
Conclusion : comment décider vite et réduire les risques
Choisir un hébergement WordPress prêt pour l’IA revient à arbitrer trois dimensions : contrôle des données, latence et coûts. Les API externes accélèrent la mise en œuvre ; les GPU privés garantissent souveraineté et maîtrise ; l’hybride réduit les transferts tout en conservant la puissance. Sur la base des signaux récents - adoptions enterprise, initiatives de clouds européens et alertes réglementaires - priorisez les vérifications contractuelles (résidence, chiffrement, SLA), réalisez des tests de latence end‑to‑end et mettez en place des mesures de minimisation/anonymisation avant d’envoyer des données vers un LLM. Pour une agence ou une DSI, la démarche pragmatique est de lancer un pilote chiffré selon l’un des scénarios proposés, documenter les preuves exigées et éviter la production de traitements sensibles sans garanties techniques et contractuelles vérifiables.
Points clés à retenir
- Un hébergement 'prêt IA' doit offrir accès maîtrisé à GPU ou connexions sécurisées aux API LLM, avec garanties contractuelles sur résidence et chiffrement.
- Trois architectures principales orientent risque et coût : intégration via API externes, LLM privé sur GPU/bare‑metal, ou architecture hybride (caches locaux + API pour tâches lourdes).
- Procédez par audit des flux, tests de latence end‑to‑end, clauses contractuelles exigeant droits d'audit et export des index, puis pilote chiffré avant production.
Foire Aux Questions
Faut‑il toujours héberger un LLM privé pour garantir la conformité ?
Pas systématiquement. Le choix dépend de la sensibilité des données, des obligations de résidence et des exigences de latence. Le document propose des scénarios (API, hybride, privé) à choisir selon ces critères.
Quels engagements demander dans le contrat d’hébergement ?
Exiger SLA pour latence et disponibilité de l’inférence, garanties de résidence et de chiffrement, droit d’audit, obligations de notification en cas de faille, et clauses de sortie pour l’export des modèles et index.
Comment vérifier techniquement qu’un hébergeur est 'prêt IA' ?
Contrôlez la disponibilité d’instances GPU ou bare‑metal, les options de connexions sécurisées (mutual TLS, VPC endpoints), la présence de traces d’audit et la documentation sur autoscaling et limites d’usage.
Quels tests réaliser avant mise en production ?
Mesurer la latence end‑to‑end et le coût par requête, évaluer le taux d’erreur d’inférence, simuler montée en charge et perte d’accès à l’API pour valider autoscaling et procédures de mitigation.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
OpenAI
Site officielEntreprise a l origine de modeles generatifs utilises pour redaction, code et assistants IA.
Samsung
Site officielActeur cite dans cet article, a completer si vous souhaitez enrichir la fiche marque.
Sources et Références
- Samsung adopte ChatGPT Enterprise et Codex à grande échelle pour transformer son organisation
- OVHcloud veut ses propres LLM
- La Norvège va interdire les chatbots IA aux écoliers
- Une faille permet d’écouter vos conversations à distance sur les Beats Studio Buds d’Apple
- OVHcloud - Instances GPU (page produit)
- AWS - Instances GPU pour apprentissage et inférence ML (ex. P4)
Pourquoi cet article
Angle proposé Contexte déclencheur (sources récentes) : Samsung a adopté ChatGPT Enterprise et Codex à grande échelle ; OVHcloud annonce vouloir ses propres LLM ; la presse technique évoque des avancées matérielles et d’infrastructure liées à l’IA (ex...








