Résumé du déclencheur et enjeu pour sites WordPress
Vous voyez soudainement des pics de trafic sans campagne marketing et vous vous demandez si des "agents IA" automatisés pointent vers votre site : baisse possible des prix des tokens, stockage cloud évolutif et intégrations IA temps réel multiplient les outils disponibles pour orchestrer des bots. Pour un propriétaire WordPress ou une agence, le problème n’est pas théorique mais opérationnel : rafales de requêtes HTTP, appels API facturés, CPU et mémoire consommés, caches vidés, latence qui explose et risque d’indisponibilité. Cet article explique comment repérer ces comportements dans vos logs et tableaux de bord, chiffrer l’impact (trafic, latence, coûts API) et appliquer des mesures prioritaires à court terme (heures) puis durables (semaines) adaptées à votre niveau technique et budget.
Conseil pratique
Un test simple pour confirmer une surcharge automatisée et déclencher une réponse minimale.
- Consultez le tableau de bord d’hébergement ou le CDN pour vérifier l’augmentation de requêtes par seconde et les erreurs 5xx.
- Exportez les 100 IP/URI les plus actives depuis les logs d’accès et cherchez des motifs répétés ou des user‑agents en rotation.
- Activez temporairement une règle de throttling ou challenge JS au niveau CDN/WAF et observez l’évolution du RPS et du taux d’erreur.
Détecter et diagnostiquer une surcharge causée par des agents IA
Signes initiaux à repérer
Surveillez d’abord les indicateurs opérationnels : augmentation soudaine des requêtes par seconde ou des sessions concurrentes sans cause interne connue, hausse des erreurs 5xx, et montée des latences p95/p99. Complétez par l’observation des ressources système-CPU et RAM proches de la saturation-et par les alertes du CDN ou du WAF qui signalent des motifs bot-like ou des dépassements de seuils.
Sources de données et commandes pratiques
Travaillez directement avec vos logs d’accès et applicatifs. Inspectez les fichiers nginx/apache (tail -n, grep par URI), exportez des échantillons et groupez par IP ou User‑Agent. Pour les logs JSON, des outils comme jq, et pour des rapports rapides GoAccess ou AWK sont utiles. Côté WordPress, vérifiez erreurs PHP, timeouts de base de données et transients invalidés. Le tableau de bord de l’hébergeur donne les métriques de process, load average et connexions simultanées. Enfin, corrélez avec le CDN/WAF : hits par edge, ratio cache hit/miss et règles déclenchées, et regardez dans les analytics si les visites exécutent du JavaScript (indicateur d’interaction humaine).
Heuristiques pour identifier des agents IA
Appliquez des heuristiques de comportement plutôt que de vous fier au seul User‑Agent. Repérez des parcours répétés : mêmes séquences d’URLs, consultées rapidement et régulièrement. Observez une diversité superficielle de User‑Agent accompagnée d’un comportement identique, ce qui peut traduire une rotation d’UA. Notez l’absence de chargement complet des ressources côté client - peu ou pas d’événements JS - et des navigations trop rapides pour un humain. Enfin, des groupes d’IP géographiquement dispersées mais partageant un même ASN ou un reverse DNS commun peuvent indiquer une origin orchestration.
Priorisation du diagnostic
Organisez le triage en trois paliers : en 15 minutes, déterminez si l’origine est interne (plugin, cron) ou externe. En une heure, collectez échantillons de logs et la liste des règles WAF déclenchées, exportez le top 100 des IP et des URI. Sur 24 heures, corrélez ces données avec les alertes de facturation API et les communications de l’hébergeur pour décider d’une mitigation forte ou d’une simple observation.
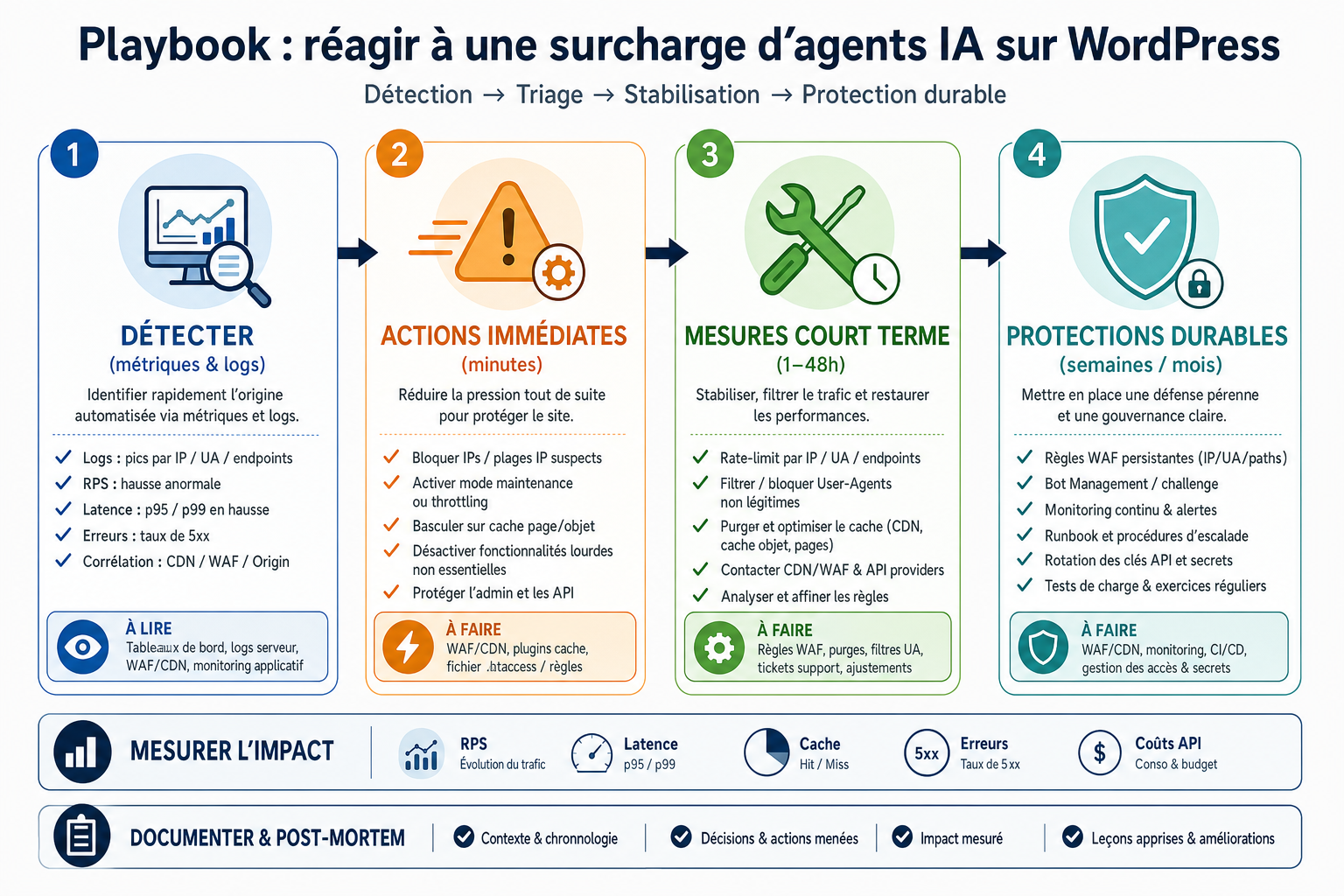
Mesurer l'impact et prioriser les réponses
Chiffrez l’impact rapidement avec un jeu de métriques actionnables : RPS moyen et pic, latence p95/p99, taux d’erreur 5xx, nombre d’IP actives uniques, ratio cache hit/miss, volume sortant en Go et nombre d’appels API externes (avec coût estimé si possible). Comparez l’évolution sur les 1, 6 et 24 dernières heures à votre baseline normale. Combinez gravité (site indisponible, coût facturé, dégradation UX) et probabilité de récurrence pour créer une matrice d’urgence : interruption de service ou coûts API imprévus exigent une mitigation immédiate ; forte dégradation UX nécessite des actions sous 1-48 heures ; scraping massif sans impact immédiat peut rester en surveillance active et blocage ciblé. Mesurez l’effort vs le risque : un blocage massif d’IP peut résoudre l’incident mais produire des faux positifs, un CAPTCHA réduit le trafic légitime. Activez les alertes de facturation chez vos fournisseurs API et posez des plafonds temporaires si possible. Documentez chaque décision (quoi, quand, par qui, effet mesuré) pour le post‑mortem et l’amélioration de vos règles.
Plans d'action opérationnels : Mitigation immédiate et durable
Mesures immédiates (minutes)
Si le site est en risque d’indisponibilité, activez le mode maintenance pour limiter l’impact utilisateur tout en protégeant l’infrastructure. Appliquez un throttling global via le CDN/WAF : rate limits par IP et par URI et bloquez temporairement les IP/ASN les plus actifs. Renforcez les règles bot‑management du CDN (challenge JS, CAPTCHA) et placez des challenges sur les formulaires critiques. Pour réduire la charge d’origine, servez au maximum le contenu statique depuis le CDN et augmentez temporairement le TTL des objets mis en cache.
Interventions à 1-48 heures
Déployez des règles personnalisées dans le WAF pour bloquer des motifs d’URI, des user‑agents suspects et des séquences de requêtes identifiées. Au niveau serveur, mettez en place nginx limit_req_zone et activez des protections comme fail2ban ; isolez les processus PHP‑FPM pour éviter que quelques requêtes n’écrasent tout le pool. Segmentez l’API : protégez les endpoints critiques par quotas, clés et limites par clé/IP. Si l’analyse montre que le coût de scaling temporaire est acceptable, demandez à l’hébergeur un renfort d’instances ou activez l’autoscaling pour absorber le pic sans impact immédiat sur les utilisateurs réels.
Mesures durables (semaines/mois)
Pour prévenir les récidives, installez un CDN robuste avec cache d’objets et règles d’edge computing capable de filtrer au plus tôt. Déployez une solution managée de gestion des bots / WAF et formalisez des playbooks d’alerte et d’intervention. Optimisez l’architecture WordPress : object cache (Redis/Memcached), cache HTML côté serveur et découplage éventuel des API les plus sollicitées. Réduisez la surface d’attaque en fermant les endpoints inutiles, en sécurisant les formulaires et en désactivant les scripts non essentiels. Mettez en place un monitoring permanent des logs, des tableaux de bord de baselines et des exercices d’incident pour valider vos procédures.
Outils pratiques et configuration recommandée
Activez les fonctions bot management et rate limiting de votre CDN/WAF et utilisez des challenges JS/CAPTCHA. Côté reverse proxy/serveur, configurez nginx avec limit_req_zone, gzip, keepalive et directives cache‑control. Sur WordPress, combinez un plugin de sécurité (par ex. Wordfence ou Sucuri), un object cache Redis et un plugin de cache HTML adapté. Pour l’analyse, GoAccess permet une vue rapide, et une stack ELK ou Datadog facilite la corrélation et les alertes sur RPS, erreurs et coûts API. Enfin, définissez une procédure d’escalade interne vers l’hébergeur lorsque CPU/IO saturent ou que des coûts dépassent un seuil attendu.
Quand faire appel à l’hébergeur ou un spécialiste
Contactez l’hébergeur si la charge affecte l’infrastructure du fournisseur, si vous n’avez pas accès aux métriques nécessaires, ou si l’attaque est persistante et ciblée. Faites appel à un spécialiste pour des attaques prolongées, un audit d’architecture ou une optimisation avancée des coûts et de la sécurité. Si l’incident génère une facture cloud significative, sollicitez l’intervention du fournisseur pour négocier des limites ou des protections au niveau réseau.
Conclusion - checklist prioritaire et pas-à-pas pour démarrer
Commencez par confirmer la nature automatisée du pic : collectez logs, calculez RPS/p95/taux 5xx et exportez le top IP/URI. Si l’impact est critique, déclenchez les mesures immédiates (maintenance, rate‑limit CDN, blocage d’IP) puis exécutez les actions 1-48h (règles WAF, quotas API, scaling) et planifiez les mesures durables (CDN, cache objet, bot management, procédures d’escalade). Activez les alertes de facturation API et documentez chaque décision avec échantillons de logs pour le post‑mortem. Rappel pratique : les signaux d’actualité mentionnés indiquent un risque accru, pas une preuve d’attaque - d’où l’importance d’une surveillance continue et de seuils d’alerte correctement calibrés.
Points clés à retenir
- Identifier rapidement une origine automatisée via logs, RPS, p95/p99, erreurs 5xx et corrélation CDN/WAF.
- Mitigation en trois paliers : actions immédiates (minutes), mesures 1-48h, et protections durables (semaines/mois).
- Mesurer l’impact (RPS, latence, cache hit/miss, coûts API) et documenter chaque décision pour le post‑mortem.
Foire Aux Questions
Quels signes indiquent qu’un pic de trafic vient d’agents IA plutôt que d’utilisateurs légitimes ?
Cherchez une hausse soudaine du RPS sans campagne marketing, des parcours répétitifs (mêmes séquences d’URL), navigation trop rapide, faible exécution d’événements JavaScript et rotation superficielle des user‑agents. Corrélez ces signes avec l’augmentation du CPU/RAM et les alertes CDN/WAF.
Quelles actions immédiates appliquer si le site risque l’indisponibilité ?
Mettre en mode maintenance si nécessaire, activer des rate limits au CDN/WAF, bloquer temporairement les IP/ASN les plus actives et relever le TTL du cache pour réduire la charge serveur.
Le blocage massif d’IP est‑il risqué pour le trafic légitime ?
Oui : un blocage large peut créer des faux positifs. Mesurez l’effort vs le risque et privilégiez des règles ciblées (URI, séquences de requêtes) ou des challenges pour réduire les impacts sur les utilisateurs réels.
Quand faut‑il contacter l’hébergeur ou faire appel à un spécialiste ?
Contactez l’hébergeur si la charge affecte l’infrastructure du fournisseur ou si vous n’avez pas accès aux métriques essentielles. Sollicitez un spécialiste pour des attaques prolongées, un audit d’architecture ou une optimisation avancée des coûts et protections.
Quelles métriques suivre pour chiffrer l’impact d’une surcharge par agents IA ?
RPS moyen et pic, latence p95/p99, taux d’erreur 5xx, nombre d’IP actives uniques, ratio cache hit/miss, volume sortant et appels API externes (avec alerte de facturation).
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Acteur majeur du web et de la recherche, souvent source des evolutions SEO et IA.
OpenAI
Site officielEntreprise a l origine de modeles generatifs utilises pour redaction, code et assistants IA.
Sources et Références
- OpenAI et Anthropic envisageraient de casser les prix des tokens
- OVHcloud et Scality : une nouvelle offre de stockage cloud
- DeepL s’invite dans Google Meet avec des sous-titres traduits en temps réel
- Meta abandonne l’IA Manus après avoir déboursé deux milliards de dollars
- Brouillon : guide opérationnel « Quand les agents IA surchargent votre site »
Pourquoi cet article
Signal d'actualité et enjeu concret - Selon Search Engine Journal, les bots et agents IA provoquent déjà des surcharges serveur et font peser des coûts supplémentaires sur les propriétaires de sites ; la même rédaction souligne par ailleurs plusieurs «...