Introduction : ce qui change pour les sites WordPress
La montée d’initiatives publiques visant à donner une identité numérique aux agents IA et les obligations de transparence du cadre européen sur l’IA imposent aux sites professionnels de repenser la façon dont ils publient et affichent du contenu automatisé. Pour un site WordPress, l’enjeu n’est pas seulement technique : il s’agit d’assurer que les visiteurs reconnaissent quand ils interagissent avec un agent, que l’éditeur conserve des preuves de provenance et que les machines puissent vérifier l’origine des réponses. Cet article détaille les enjeux concrets, les briques techniques et éditoriales adaptées à WordPress, et une feuille de route opérationnelle pour intégrer des métadonnées d’identité d’agent, exposer des endpoints dédiés, marquer la provenance des contenus avec W3C PROV et schema.org, et afficher des mentions claires aux visiteurs, afin que responsables web ou marketing puissent prioriser et lancer des actions mesurables.
Conseil pratique
Un test rapide vous permet de vérifier l'affichage, l'indexation et la traçabilité sans repenser tout le site.
- Identifier un point d'entrée simple (page de chat ou FAQ) où l'agent intervient.
- Créer un enregistrement minimal 'Agent' (identifiant, opérateur, champ de provenance) dans WordPress ou comme post_meta.
- Afficher une mention visible sur l'interface (bandeau ou étiquette) et ajouter un JSON‑LD dans le head reprenant creator/generator et éléments de provenance.
Ce que l’identité numérique d’un agent change pour votre site
Quelles obligations et quels risques pour l’éditeur
Un agent doté d’une identité numérique change la responsabilité éditoriale : il faudra informer explicitement les utilisateurs lorsqu’ils interagissent avec un agent IA ou reçoivent un contenu généré par lui, et conserver des preuves de cette provenance. La transparence attendue au niveau européen signifie que les labels et métadonnées devront être accessibles et vérifiables pour des tiers. Si l’origine des contenus n’est pas lisible, le risque principal est la perte de confiance des utilisateurs. Sur le plan opérationnel, l’absence de traçabilité complique la remontée d’incidents, les révisions et la justification des décisions prises sur la base de contenus automatisés.
Impacts techniques sur votre architecture WordPress
Sur WordPress, accueillir des agents identifiés nécessite d’exposer des métadonnées structurées liées aux contenus et aux entités agents. Concrètement cela passe par des métas post, des custom post types ou des métas utiliateur qui stockent l’identifiant de l’agent, son opérateur et la chaîne de génération. Il faut prévoir des endpoints REST publiques ou internes qui retournent l’identifiant de l’agent et une représentation de provenance sérialisée, par exemple conforme au modèle W3C PROV. Le balisage JSON‑LD conforme à schema.org permettra de rendre ces informations lisibles par les moteurs et par d’autres agents automatisés. Enfin, il est nécessaire d’ajouter des journaux d’activité pour horodater et hacher les événements de génération, ainsi que des mécanismes d’authentification (clé API, JWT ou mécanismes équivalents) pour lier l’identité d’un agent à son opérateur et vérifier la chaîne d’origine.
Conséquences éditoriales et SEO
Côté contenu, chaque article ou réponse produite ou modifiée par un agent doit porter un signal visible pour l’utilisateur et un balisage machine pour le référencement et la consommation par agrégateurs. Un libellé clair et constant, affiché en tête d’article ou dans l’interface de chat, améliore la confiance et réduit la confusion. Il est utile de distinguer les attributs d’auteur (humain versus agent) et d’appliquer des règles d’édition qui imposent une relecture humaine pour les contenus sensibles. Le balisage schema.org en JSON‑LD renseignant creator, generator et éléments de provenance permet de garder la trace des responsabilités tout en aidant les moteurs à interpréter correctement la source des contenus.
Qui est concerné et priorités métier
Tous les sites professionnels qui publient ou intègrent des réponses automatisées sont concernés : sites médias, plateformes de support client, boutiques en ligne et blogs d’entreprise. La priorité doit aller aux points de contact directs avec les utilisateurs, comme les chatbots et les FAQ dynamiques, puis aux contenus générés en masse. L’objectif opérationnel est simple : garantir la visibilité utilisateur, conserver des preuves vérifiables et assurer l’interopérabilité machine pour faciliter audits et vérifications ultérieures.
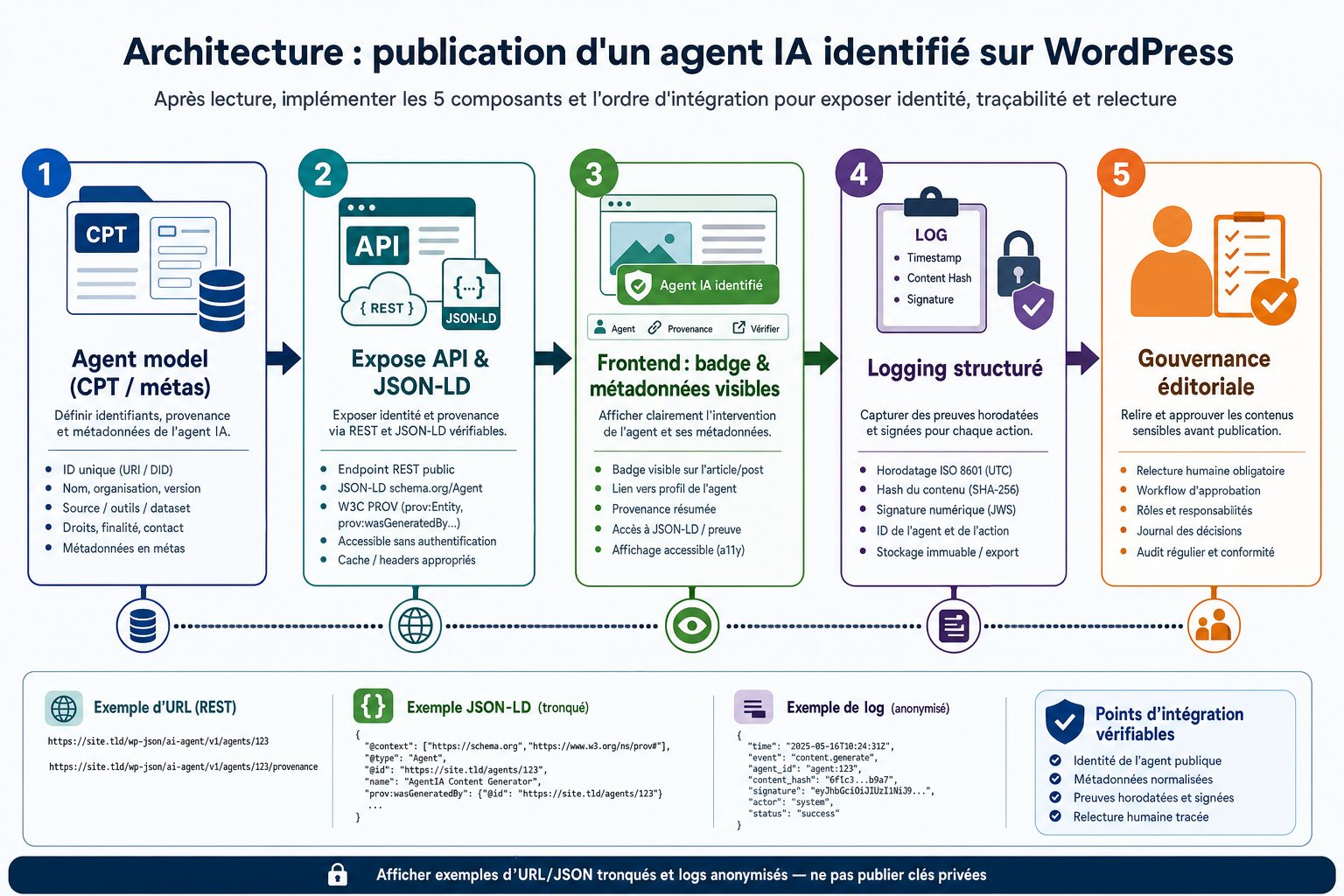
Briques techniques prioritaires à déployer sur WordPress
Pour rendre opérante l’identité numérique des agents sur un site WordPress, déployez un ensemble cohérent de composants : un custom post type "Agent" ou des métas utilisateur pour stocker id, opérateur, capacités et règles ; un endpoint REST (par exemple /wp-json/ia/v1/agents/{id}) qui retourne l’identité et la provenance sérialisée selon W3C PROV ; un balisage JSON‑LD conforme à schema.org intégrant creator/generator et champs de provenance pour le SEO ; un système de journalisation structuré (logs ou table dédiée) qui enregistre horodatage et hash de contenu ; des mécanismes d’authentification et de signature pour lier un identifiant d’agent à son opérateur ; des composants frontend pour afficher une mention visible à l’utilisateur (badge, bandeau, texte en tête de contenu) ; et enfin une procédure de gouvernance éditoriale précisant rôles, relecture humaine et règles de suppression. Ces briques s’appuient sur les fonctionnalités natives de WordPress (REST API, metadata, custom post types) et sur des standards ouverts pour garantir interopérabilité et traçabilité.
Plan d’action opérationnel : étapes à suivre
Phase 1 - audit et choix des schémas
Commencez par recenser les points du site où des agents IA interviennent : chat, génération d’articles, recommandations, notifications personnalisées. Identifiez les flux à risque et priorisez les interfaces visibles. Choisissez ensuite un modèle d’identité adapté : créer un custom post type "Agent" avec des champs structurés (identifiant, opérateur, version, capacités, règles de gouvernance) et une représentation de provenance basée sur W3C PROV. Déterminez les éléments visibles destinés aux visiteurs (texte de mention et emplacement) et listez les métadonnées qui devront être exposées via JSON‑LD pour les moteurs et APIs externes.
Phase 2 - implémentation technique concrète
Créez le CPT "Agent" et les métadonnées nécessaires, puis ajoutez un endpoint REST dédié, par exemple /wp-json/ia/v1/agents/{id}, qui retourne l’identité et une structure PROV en JSON. Lors de chaque génération, liez le post créé ou modifié à l’agent via post_meta (agent_id, provenance_hash, timestamp). Intégrez dans le head du site un JSON‑LD automatique qui renseigne creator/generator et inclut les champs PROV pertinents pour l’indexation. Mettez en place un logging structuré, fichier ou table, qui enregistre les événements de génération, les requêtes API et les signatures; prévoyez des outils de rotation et d’export pour faciliter les audits.
Phase 3 - mentions utilisateur et gouvernance éditoriale
Définissez un libellé normalisé visible pour les visiteurs, par exemple "Contenu généré par un agent IA identifié : [Nom] - Opérateur : [Opérateur]", et décidez des emplacements prioritaires (début d’article, encart chat, page de résultats). Établissez une règle de relecture humaine pour les contenus sensibles et désignez un rôle WordPress responsable de la supervision et des validations. Documentez une politique de transparence accessible publiquement et placez un lien vers cette politique depuis les mentions visibles.
Phase 4 - tests, conformité et surveillance continue
Testez les endpoints et le JSON‑LD avec des validateurs et vérifiez la lisibilité par les moteurs et outils d’indexation. Contrôlez la robustesse des logs et la capacité à reconstruire la chaîne de production à partir des métadonnées et des hachages. Mettez en place des alertes sur anomalies (modifications non signées, contenus publiés sans agent lié) et planifiez des revues périodiques pour adapter le schéma aux évolutions réglementaires ou techniques. Documentez les procédures d’incident pour assurer traçabilité et responsabilité en cas de réclamation.
Conclusion
Anticiper l’arrivée d’agents IA avec identité numérique sur WordPress est une démarche pragmatique et réalisable. Les actions clés sont : cartographier les usages IA du site, implémenter un modèle d’agent (CPT/métas) et un endpoint REST exposant la provenance, afficher une mention utilisateur claire et systématique, et activer un logging structuré avec relecture humaine pour les cas sensibles. Ces mesures garantissent une visibilité pour les visiteurs, une traçabilité pour l’éditeur et une interopérabilité machine utile pour la conformité. En priorisant points de contact utilisateur et mécanismes de preuve, vous limitez les risques et facilitez la montée en régime des services automatisés tout en restant transparent et responsable.
Points clés à retenir
- Afficher aux visiteurs quand un agent IA intervient et exposer des métadonnées vérifiables pour la provenance des contenus.
- Sur WordPress, créer un modèle d'agent (CPT ou métas) et exposer l'identité et la provenance via un endpoint REST et du JSON‑LD conforme à schema.org/W3C PROV.
- Mettre en place du logging structuré (horodatage, hash, signatures) et une gouvernance éditoriale avec relecture humaine pour les contenus sensibles.
Foire Aux Questions
Faut-il indiquer quand un contenu ou une réponse provient d’un agent IA ?
Oui. Le texte analysé indique qu’il faut informer explicitement les utilisateurs lorsqu’ils interagissent avec un agent IA ou reçoivent un contenu généré par lui, et conserver des preuves de cette provenance.
Quel format choisir pour exposer la provenance machine‑readable ?
Le brouillon recommande d’utiliser du JSON‑LD conforme à schema.org pour le SEO et une représentation de provenance sérialisée selon le modèle W3C PROV exposée via un endpoint REST.
Où stocker l’identité et l’historique d’un agent dans WordPress ?
Les options proposées sont un custom post type 'Agent', des métas post (post_meta) ou des métas utilisateur. Chaque génération peut être liée via des champs (agent_id, provenance_hash, timestamp).
Quelles parties du site prioriser en premier ?
Priorisez les points de contact directs avec les utilisateurs : chatbots, FAQ dynamiques et interfaces de support, puis les contenus publiés en masse, afin d’assurer visibilité et traçabilité là où l’impact utilisateur est immédiat.
Comment vérifier la chaîne de production en cas d’incident ?
Le texte préconise un logging structuré qui enregistre horodatage et hash des événements, ainsi que des mécanismes d’authentification et de signature liant l’identifiant de l’agent à son opérateur pour reconstruire la chaîne de production.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Acteur majeur du web et de la recherche, souvent source des evolutions SEO et IA.
Schema.org
Site officielStandard de donnees structurees utilise pour aider moteurs et IA a comprendre le contenu.
Microsoft Copilot
Site officielAssistant IA de Microsoft integre aux usages bureautiques, recherche et developpement.
Sources et Références
Pourquoi cet article
Angle proposé Sujet déclencheur : Next.ink rapporte que l’Estonie souhaite attribuer une identité numérique à chaque agent IA. Ce signal, couplé à la montée des assistants et outils IA (GitHub Copilot, Midjourney, fonctions IA intégrées aux plateformes) et...