

Héberger l'inférence IA en agence WordPress : ce que l'actualité rend possible
Pour une agence WordPress, l'idée d'exécuter l'inférence des modèles d'IA « en propre » devient réaliste grâce à deux évolutions techniques observables : la disponibilité de modèles à poids ouverts, citons Llama 2 publié par Meta, et l'essor de runtimes optimisés pour matériel grand public, comme llama.cpp et GGML. Ces éléments ciblent explicitement l'exécution des modèles, non leur entraînement massif. Concrètement, cela ouvre la possibilité d'héberger un service d'inférence sur site ou sur un serveur contrôlé par l'agence, avec des bénéfices attendus en maîtrise des données clients, baisse potentielle des coûts récurrents liés aux API externes selon les profils d'usage, et latence réduite pour des fonctions intégrées aux sites. Le gain réel dépendra du modèle choisi, du runtime et du matériel disponible ; ce texte propose un chemin opérationnel pour évaluer et piloter cette option sans engager d'efforts irréversibles.
Conseil pratique
Un premier test rapide permet de valider la valeur, la latence et la charge sans engager l'industrialisation.
- Définir un cas clair et limité (ex. chatbot interne ou recherche sémantique) et les critères de succès.
- Choisir un runtime CPU pour prototype (ex. llama.cpp/GGML) et un modèle à poids ouverts compatible.
- Déployer le modèle en container, exposer une API interne et connecter un plugin WordPress pour mesurer latence et coût.
Bénéfices métier et limites pratiques pour une agence WordPress
Avantages concrets pour l'agence et ses clients
Héberger l'inférence en local réduit les transferts de données vers des tiers et facilite le contrôle des flux sensibles, ce qui est un argument commercial pour des secteurs exigeants en confidentialité, comme la santé ou la finance. La maîtrise de l'infrastructure permet d'optimiser la latence pour des interactions en temps réel sur les sites, par exemple pour des chatbots ou une recherche sémantique intégrée. À usage intensif, l'absence de facturation à la requête d'un tiers peut aussi réduire les coûts récurrents, selon le volume et le profil des appels. Enfin, l'existence de modèles open weights et de runtimes CPU/GPU accessibles abaisse la barrière d'entrée technique et juridique pour un déploiement local, sous réserve de respecter les licences applicables.
Limites techniques et scénarios non réalistes
L'approche locale concerne l'inférence, pas l'entraînement massif : entraîner des modèles de grande taille reste hors de portée pour une plupart des agences sans infrastructures spécialisées. La capacité opérationnelle dépend de la taille du modèle, du nombre d'appels simultanés et du matériel : des charges très concurrentes ou des besoins de génération lourde peuvent rester plus efficaces en cloud. De plus, maintenir un service d'inférence fiable implique des compétences en exploitation, monitoring et gestion des conteneurs que toutes les agences n'ont pas forcément en interne.
Risques réglementaires et gestion de la confidentialité
Héberger localement peut faciliter la conformité en limitant les transferts de données personnelles, mais n'autorise pas à ignorer les obligations légales : il faut informer les clients, identifier la base légale du traitement et appliquer des mesures techniques et organisationnelles adaptées. Les logs et les sauvegardes doivent être traités avec précaution, et une évaluation préalable des données à traiter et des garanties techniques est recommandée, en se référant notamment aux recommandations de la CNIL.
Cas d'usage prioritaires pour vos sites clients
Commencez par des cas à valeur ajoutée claire et à risque limité : chatbots intégrés pour support client, recherche sémantique sur le catalogue produit, suggestions de contenu et assistants de rédaction pour pages ou fiches produit offrent des gains immédiats en latence et confidentialité. La classification automatique des commentaires ou des formulaires, ainsi que les résumés de documents clients, sont aussi bien adaptés à l'inférence locale. Évitez d'industrialiser l'ensemble des usages IA d'un client d'emblée : prioriser un service mesurable, par exemple un chatbot interne ou une recherche améliorée, permet de valider la charge, la latence et l'économie avant d'étendre le périmètre.
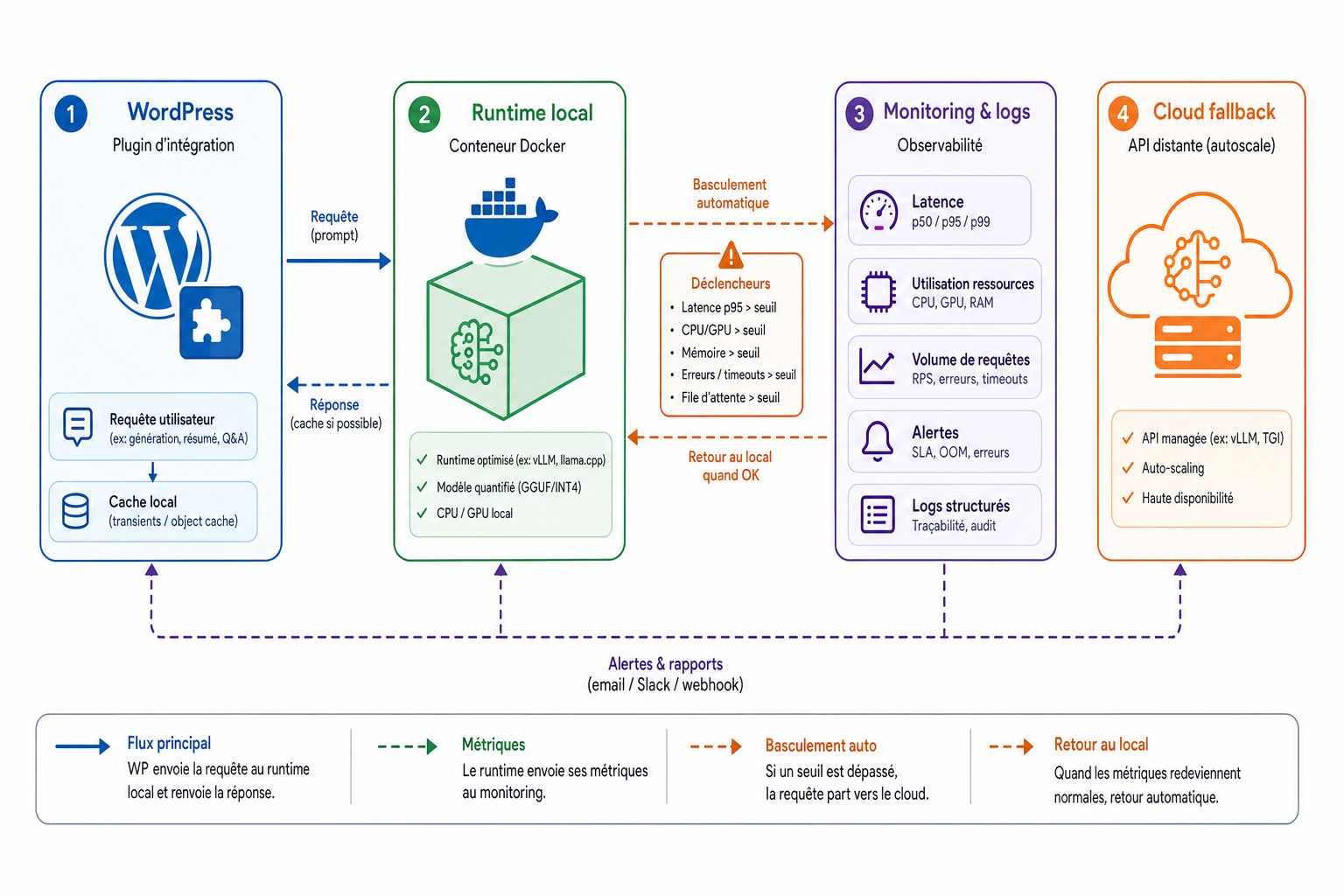
Plan opérationnel pas-à-pas : matériel, logiciel et intégration WordPress
Étape 1 - Choisir l'échelle et le matériel
Commencez par définir le périmètre : nombre d'appels simultanés attendus, tolérance de latence et exigences de confidentialité. Pour des prototypes et charges légères, un runtime CPU-optimisé comme llama.cpp/GGML peut suffire. Pour des besoins de production sensibles à la latence, préférez une machine équipée d'un GPU grand public compatible ou un serveur dédié hébergé physiquement par l'agence. Prévoyez évolutivité et ventilation thermique, et réfléchissez dès le départ à une stratégie hybride qui bascule vers le cloud si la charge dépasse les capacités locales.
Étape 2 - Choisir le modèle et le runtime
Sélectionnez un modèle en fonction du compromis taille/capacité de génération et des ressources disponibles. Les modèles à poids ouverts permettent un déploiement local sous leur licence respective ; vérifiez les conditions d'utilisation avant tout déploiement. Adaptez le runtime au matériel : llama.cpp/GGML pour CPU ou configurations modestes, runtimes GPU et images containerisées pour des machines équipées. Containeriser le service (Docker) facilite le déploiement, la mise à jour et le rollback.
Étape 3 - Architecture d’intégration avec WordPress
Exposez le modèle comme un service HTTP interne (API REST ou gRPC) sur le réseau contrôlé par l'agence. Côté WordPress, implémentez un plugin ou un microservice intermédiaire pour orchestrer les appels et protéger le service.
- centraliser les appels IA pour gérer pooling et mise en file,
- authentifier et appliquer des quotas par site ou par client,
- mettre en cache les réponses coûteuses pour réduire la charge,
- prévoir un routage de secours vers une API cloud en cas de saturation du service local.
Ajoutez un reverse proxy pour sécuriser l'accès et un système de queue pour lisser les pics. Documentez les points d'API et fournissez des métriques de latence côté plugin pour évaluer l'impact sur l'expérience utilisateur.
Étape 4 - Exploitation, sécurité et sauvegarde
Mettez en place du monitoring pour CPU/GPU, mémoire, usage disque et latence des endpoints, couplé à de l'alerting. Automatisez les redémarrages et les rollback via containers. Sauvegardez configurations et versions de modèles, mais traitez les données clients avec précaution : anonymisation ou minimisation des logs, contrôles d'accès stricts et chiffrement au repos si nécessaire. Préparez des procédures de maintenance, de tests de charge et de restauration avant mise en production.
Étape 5 - Pilote, mesure et montée en charge
Lancez un pilote sur un cas réduit et mesurable. Mesurez latence, coûts opérationnels et satisfaction client. Ajustez le choix du modèle, les politiques de cache et le dimensionnement matériel à partir des mesures réelles. Si la demande augmente, évaluez une architecture hybride ou l'externalisation partielle pour maintenir la qualité de service sans surinvestir.
Conclusion - premiers pas recommandés
Pour une agence WordPress, déployer l'inférence localement est aujourd'hui une option viable pour des usages ciblés : contrôle des données, latence réduite et argument différenciant en matière de confidentialité. La meilleure approche reste progressive : démarrer par un pilote (chatbot ou assistant de contenu), évaluer les capacités matérielles et les coûts opérationnels, et vérifier les obligations CNIL avant de traiter des données sensibles. Si le pilote confirme l'intérêt, industrialisez via containers, monitoring et une intégration WordPress centralisée, tout en conservant un plan de secours cloud pour garantir la continuité de service.
Points clés à retenir
- La disponibilité de modèles à poids ouverts et de runtimes optimisés rend l'inférence locale réaliste pour des usages ciblés.
- Hébergement local apporte contrôle des données, latence réduite et potentielle réduction des coûts, mais dépend fortement du modèle, du runtime et du matériel.
- Déployer en interne nécessite une approche progressive : pilote mesurable, monitoring, containers, et plan de secours cloud ; l'entraînement massif reste hors de portée.
Foire Aux Questions
Est-ce réaliste d'héberger l'inférence IA dans une agence WordPress ?
Oui pour l'inférence sur des cas ciblés : la combinaison de modèles à poids ouverts et de runtimes optimisés permet un déploiement local viable. En revanche, l'entraînement massif de grands modèles reste hors de portée pour la plupart des agences.
Comment intégrer le service d'inférence avec WordPress ?
Exposez le modèle comme un service HTTP interne (API REST ou gRPC) et utilisez un plugin ou un microservice pour centraliser les appels, gérer l'authentification, le cache et le routage de secours vers le cloud.
Quelles compétences et opérations sont nécessaires pour maintenir le service ?
Exploitation de containers, monitoring CPU/GPU et latence, gestion des sauvegardes et des versions de modèle, procédures de rollback et tests de charge sont nécessaires pour garantir fiabilité et montée en charge.
Quelles précautions prendre côté confidentialité et conformité ?
Informez les clients, identifiez une base légale pour le traitement, minimisez et anonymisez les logs si possible, et appliquez mesures techniques et organisationnelles en vous référant aux recommandations de la CNIL.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
CNIL
Site officielAutorite francaise de reference pour la protection des donnees personnelles et la conformite.
Sources et Références
- Héberger un datacenter chez soi est la nouvelle visée en matière d'IA. Les avantages pour les propriétaires incluent l'électricité et Internet à des tarifs préférentiels. Cette approche se limite à l'inférence.
- Llama 2 - communications officielles de Meta (modèles disponibles pour usage local/commercial)
- llama.cpp (dépôt open source facilitant l'exécution locale/CPU de LLaMA-like models)
- Towards Speed-of-Light Text Generation with Nemotron-Labs Diffusion Language Models
- Intelligence artificielle et protection des données personnelles (page CNIL)
- Brouillon : Héberger l'inférence IA en agence WordPress
Pourquoi cet article
Déclencheur éditorial récent : plusieurs fils d'actualité signalent une mutation discrète mais structurante - l'idée d'héberger un « datacenter » domestique pour exécuter des modèles (inférence) et l'apparition de mini-PC/boîtiers IA performants. Sources clés...








