

Les moteurs génèrent des réponses - quel risque pour vos pages WordPress ?
Si vous gérez un site WordPress, vous avez peut‑être vu des extraits ou des « overviews » de pages apparaitre dans les résultats de recherche, parfois sous forme de résumés ou de réponses agrégées. Ces réutilisations peuvent diminuer votre trafic direct, poser des questions de droits d’auteur ou diffuser des passages hors de leur contexte éditorial. Il n’existe pas, dans la documentation publique consultée, de balise « no‑AI » officielle garantissant l’exclusion d’une page des réponses générées : les leviers aujourd’hui disponibles sont les contrôles classiques d’indexation et d’extraits (meta robots noindex / nosnippet, l’attribut data‑nosnippet pour fragments HTML et l’en‑tête HTTP X‑Robots‑Tag pour ressources non‑HTML). En pratique, appliquer ces directives réduit fortement la surface d’utilisation de vos contenus dans les réponses générées, mais l’impact exact sur les systèmes internes des moteurs peut varier et doit être validé par des tests et une surveillance continue.
Conseil pratique
Lancez un test simple pour vérifier l’effet des balises sur un échantillon de pages.
- Sélectionnez 10-50 pages représentatives (paywall, profils, pages à faible valeur).
- Appliquez noindex ou nosnippet via votre plugin SEO (ou meta robots dans l’en‑tête) sur cet échantillon.
- Vérifiez avec l’inspection d’URL de Google Search Console que les directives sont détectées et surveillez l’évolution du crawl et du trafic pendant 2-4 semaines.
Choisir quelles pages exclure : méthode opérationnelle et règles simples
Étape 1 - inventaire et catégorisation
Commencez par dresser un inventaire priorisé des pages et contenus : pages d’administration, profils privés, contenus sous paywall, contenus sous licence, pages générées automatiquement ou à faible valeur ajoutée, et contenus sensibles. Pour chaque type, identifiez un propriétaire métier (marketing, juridique, produit) qui validera la décision d’exclusion. Classez chaque catégorie selon deux critères simples : impact SEO potentiel et risque éditorial ou légal. Cette cartographie permet de cibler d’abord les cas à risque élevé sans perturber des pages stratégiques.
Étape 2 - règles recommandées par type de page
Appliquez des règles claires et différenciées. Pour les pages sensibles ou protégées (paywall, profils privés), privilégiez noindex combiné à nosnippet afin d’empêcher à la fois l’indexation et l’affichage d’extraits. Pour les contenus sous licence ou susceptibles d’être repris, ajoutez nosnippet ou data‑nosnippet sur les fragments critiques ; envisagez noindex si la page n’apporte pas de valeur pour la recherche. Les pages à faible valeur SEO (pages techniques internes, doublons, contenus générés automatiquement) doivent généralement être noindex ; si vous souhaitez qu’elles restent indexées mais sans extrait, appliquez nosnippet. Pour les ressources non‑HTML (PDF, images), utilisez X‑Robots‑Tag côté serveur pour indiquer noindex ou nosnippet sans modifier le fichier. Évitez de compter uniquement sur robots.txt : il bloque le crawl mais n’empêche pas qu’une URL soit mentionnée si d’autres sources la citent.
Étape 3 - matrice décisionnelle et gouvernance
Formalisez une matrice simple (type de page × action recommandée) et faites valider ce cadre par l’équipe juridique. Définissez qui peut modifier ces balises : quels rôles sont autorisés (développeurs, équipes SEO, responsables contenu) et quel workflow appliquer (ticket avec justification, contrôle avant mise en production). Documentez les exceptions - par exemple des pages marketing stratégiques qui doivent rester indexées - et consignez la logique pour éviter des changements non coordonnés.
Points de vigilance
Rappelez dans vos procédures que la documentation publique ne cite pas de balise « no‑AI » dédiée : les leviers mentionnés sont ceux disponibles aujourd’hui. Mesurez toujours l’impact sur le trafic avant et après tout déploiement massif, en privilégiant des tests A/B sur échantillons. Si l’objectif est d’empêcher l’utilisation de vos contenus pour l’entraînement de modèles de tiers, la voie la plus fiable reste contractuelle ou juridique ; les contrôles techniques publics ne garantissent pas cette protection.
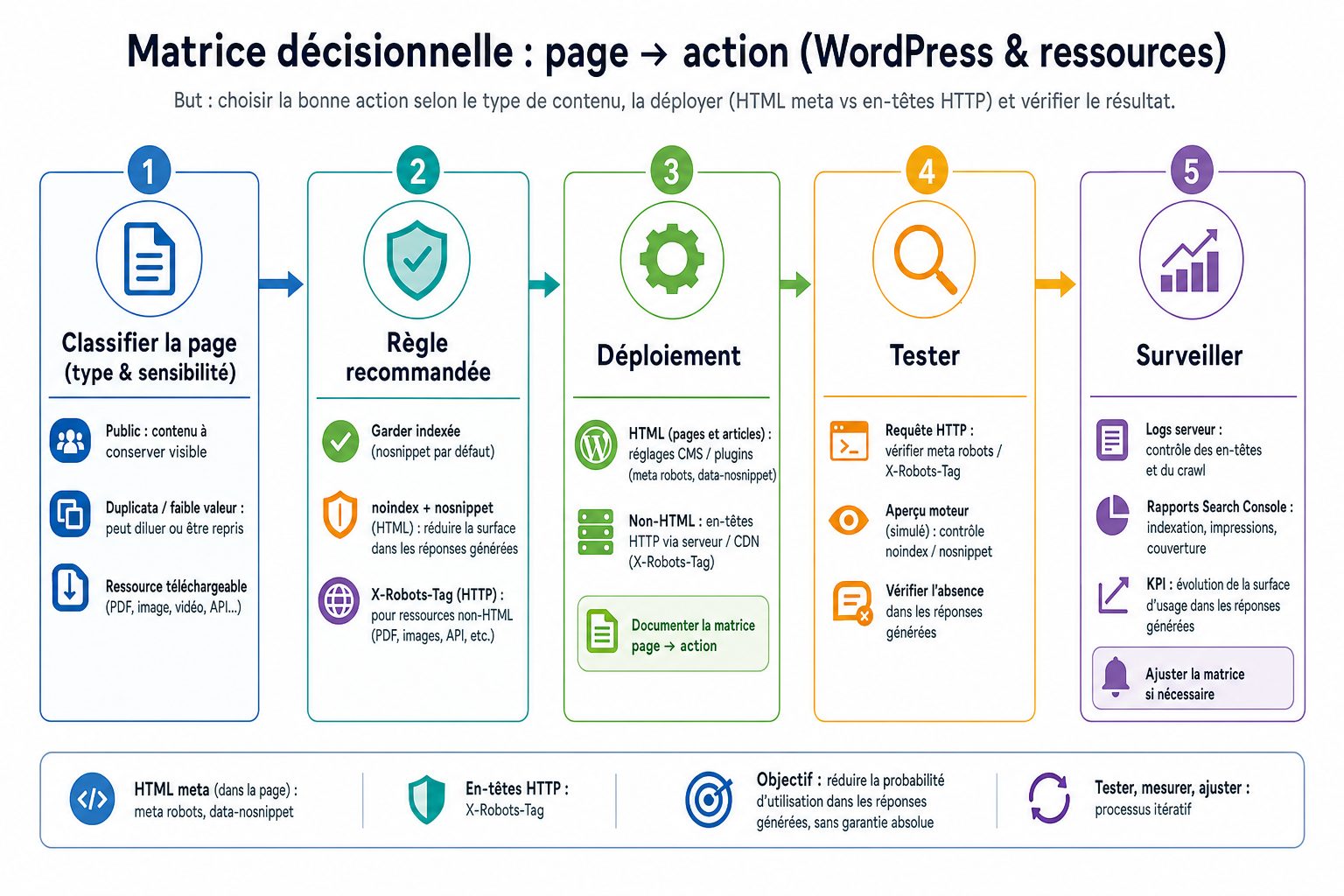
Déployer sur WordPress et pour les ressources non‑HTML
Sur WordPress, la mise en place s’effectue par deux canaux complémentaires : les réglages CMS/plugins pour le contrôle fine‑grain des pages HTML, et les en‑têtes HTTP pour les ressources non‑HTML. Utilisez l’option Search Engine Visibility du cœur WordPress pour un basculement global temporaire, ou configurez les réglages des plugins SEO (Yoast, Rank Math) pour définir noindex, nosnippet et autres directives par article, type de contenu ou taxonomie. Ces plugins permettent d’automatiser des règles - par exemple noindex sur certaines archives ou pages vides - et d’exporter/importer des paramètres lors d’un déploiement en agence. Pour les PDF, images et autres assets, appliquez X‑Robots‑Tag via la configuration serveur ou le CDN : règles d’en‑têtes dans Apache ou Nginx, ou paramètres d’en‑têtes dans le panneau du CDN, permettent d’imposer noindex/nosnippet sans toucher aux fichiers. En agence, industrialisez la mise en œuvre avec un script d’audit initial, un lot d’exemples pour tests et une procédure claire (export de réglages plugin ou snippets serveur) pour répéter l’opération sur plusieurs sites. Enfin, prévoyez un rollback simple et documenté avant tout changement massif.
Tester et surveiller les effets : protocole précis pour agences
Tests initiaux à conduire
Avant tout déploiement global, appliquez vos règles sur un échantillon représentatif de pages (par exemple 10-50 pages couvrant chaque type identifié). Utilisez l’inspection d’URL de Google Search Console pour vérifier que la meta robots ou l’en‑tête X‑Robots‑Tag est détecté et pour observer l’état d’indexation. Contrôlez le rendu avec l’outil d’inspection pour confirmer l’absence d’extraits et, pour les fragments sensibles, vérifiez que data‑nosnippet est présent dans la version rendue pour les bots.
Surveillance opérationnelle continue
Mettez en place des contrôles automatisés qui parcourent régulièrement les pages critiques pour vérifier la présence et la cohérence des balises et en‑têtes (cron + alertes). Analysez les logs serveur pour suivre le comportement des crawlers : la fréquence de crawl et les codes de réponse renseignent sur une réévaluation éventuelle des pages. Surveillez Search Console pour repérer des indexations non souhaitées et pour suivre l’évolution des clics et impressions sur les pages modifiées. Complétez ces outils par requêtes de contrôle manuelles pour vérifier si des extraits apparaissent toujours dans les résultats ou dans les overviews générés par les moteurs.
Interpréter les résultats et workflows de correction
Si une URL reste indexée malgré un noindex, vérifiez l’en‑tête HTTP X‑Robots‑Tag, l’absence de directives contradictoires (canonical pointant vers une version indexée, ou règles spécifiques dans robots.txt) et que la page rendue contient bien la balise attendue. Si des extraits persistent, assurez‑vous que nosnippet ou data‑nosnippet sont présents sur la version servie au robot et qu’il n’existe pas de variante de page servie différemment aux bots. Documentez chaque test (dates, pages, modifications), conservez captures d’écran et rapports et remontez les impacts trafic aux décideurs métier pour ajuster la stratégie si nécessaire.
Conclusion - règles simples, limites et prochaines étapes
Pour limiter l’apparition de vos pages dans les réponses générées par les moteurs, appliquez une politique claire : cartographiez les pages, validez une matrice page→action, et déployez les balises disponibles (meta robots noindex/nosnippet, data‑nosnippet, X‑Robots‑Tag) via WordPress et serveur. Testez d’abord sur échantillons et surveillez avec Search Console et logs avant tout déploiement massif. Gardez à l’esprit les limites actuelles : pas de balise « no‑AI » officielle et robots.txt ne suffit pas pour empêcher toute mention d’une URL. Formalisez les responsabilités et prévoyez des revues régulières, et consultez le juridique si l’objectif est d’empêcher l’usage des contenus pour l’entraînement de modèles.
Points clés à retenir
- Il n’existe pas, selon la documentation publique mentionnée, de balise « no‑AI » officielle ; les leviers disponibles sont meta robots (noindex/nosnippet), data‑nosnippet et X‑Robots‑Tag.
- Appliquer noindex/nosnippet réduit fortement la surface d’utilisation des contenus dans les réponses générées, mais l’impact exact varie et doit être validé par des tests et une surveillance.
- Sur WordPress, combinez réglages CMS/plugins pour HTML et en‑têtes HTTP (X‑Robots‑Tag) pour les ressources non‑HTML ; formalisez une matrice page→action et un workflow de gouvernance.
Foire Aux Questions
Existe‑t‑il une balise « no‑AI » pour empêcher l’usage des pages dans les réponses générées ?
Non : la documentation publique consultée ne mentionne pas de balise « no‑AI » officielle. Les contrôles disponibles cités sont meta robots (noindex/nosnippet), data‑nosnippet et X‑Robots‑Tag.
Robots.txt suffit‑il pour empêcher qu’une URL apparaisse dans des overviews ou extraits ?
Non : robots.txt bloque le crawl mais ne garantit pas qu’une URL ne soit pas mentionnée si d’autres sources la citent. Les directives meta et les en‑têtes sont nécessaires pour contrôler l’affichage d’extraits.
Ces mesures empêchent‑elles que mes contenus servent à l’entraînement de modèles tiers ?
Les contrôles techniques publics réduisent l’exposition, mais ne garantissent pas l’exclusion de contenus pour l’entraînement. Le brouillon indique que la voie la plus fiable pour bloquer cet usage passe par des accords contractuels ou des démarches juridiques.
Comment vérifier rapidement que mes balises fonctionnent sur WordPress ?
Appliquez la directive via votre plugin SEO ou manuellement, puis utilisez l’outil d’inspection d’URL de Google Search Console pour voir si la meta robots ou l’en‑tête X‑Robots‑Tag est détecté et si la page est indexée ou affiche des extraits.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Acteur majeur du web et de la recherche, souvent source des evolutions SEO et IA.
Yoast SEO
Site officielExtension WordPress de reference pour le SEO editorial, technique et structurel.
Rank Math
Site officielExtension SEO WordPress orientee optimisation technique, schema et pilotage de contenu.
Pourquoi cet article
Pourquoi ce sujet maintenant : des flux récents signalent que Google propose désormais une option d’exclusion pour les contenus utilisés dans ses réponses génératives (Search Engine Journal), tandis que d’autres articles évoquent la montée des « visiteurs IA...








