

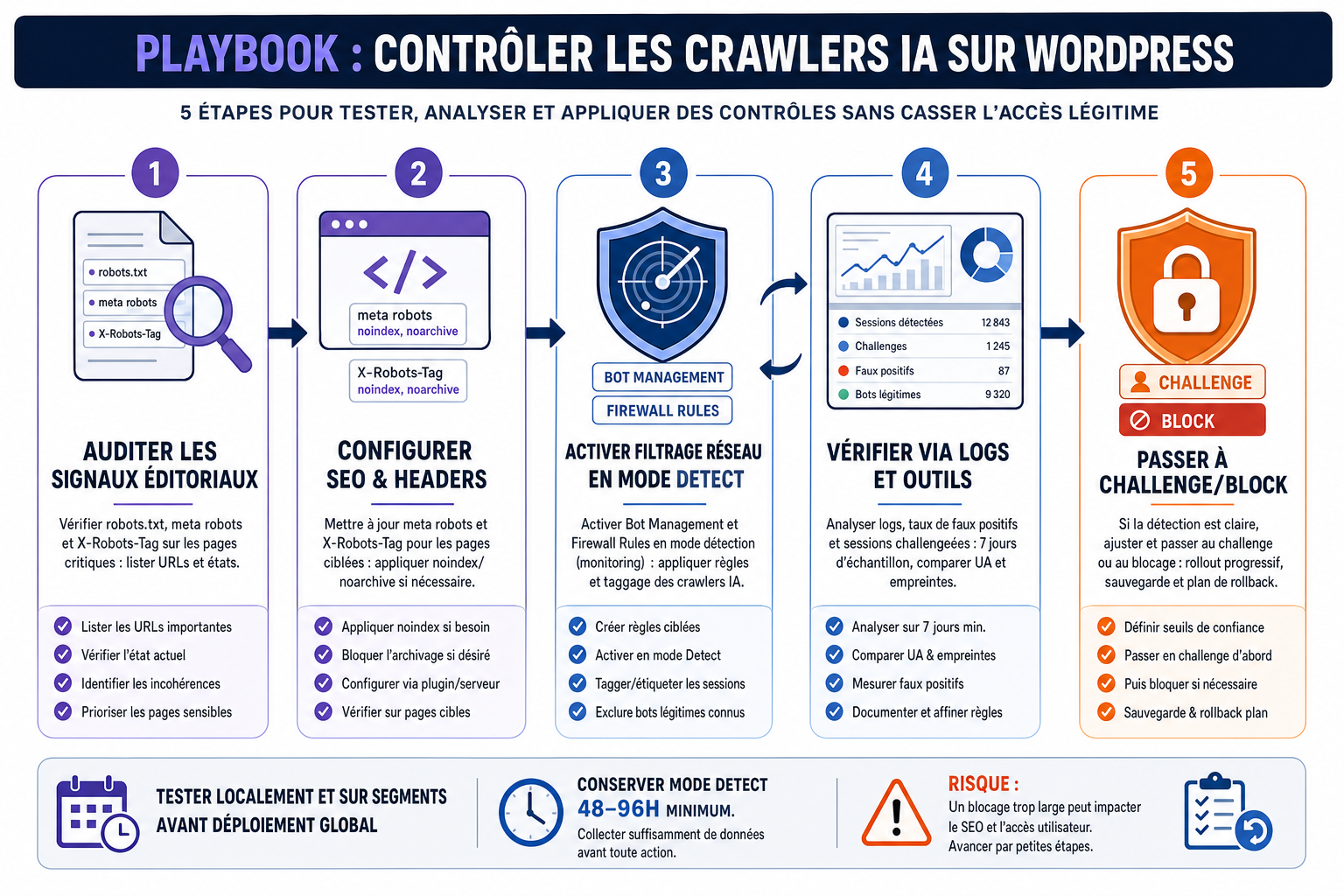
Contrôler l’accès des « crawlers » IA : enjeu et cadre pour les éditeurs WordPress
Les discussions publiques sur l’usage de contenus web pour entraîner des modèles d’IA ont rendu concret pour les éditeurs le problème du « qui copie quoi » : au‑delà du SEO classique, certains crawlers automatisés collectent massivement des pages pour l’entraînement. Techniquement, les leviers restent connus et complémentaires : robots.txt, meta robots et en‑têtes X‑Robots‑Tag pour indiquer vos souhaits d’indexation, réglages natifs WordPress et protections réseau côté CDN/WAF (par exemple Cloudflare). Ces signaux sont volontaires et peuvent être contournés (usurpation de User‑Agent, crawlers qui ignorent robots.txt), d’où l’intérêt d’une stratégie combinée - règles éditoriales claires, configuration des plugins SEO, puis filtrage actif au niveau du réseau. Enfin, si Cloudflare ou beehiiv annoncent des outils dédiés aux « AI crawlers », vérifiez directement les billets et la documentation produit avant tout déploiement.
Conseil pratique
Un test simple en quatre actions pour passer de la théorie à une première protection mesurable.
- Identifiez 1 à 3 pages à protéger et définissez leur statut (indexable / noindex).
- Ajoutez noindex/meta robots ou X‑Robots‑Tag sur ces pages et vérifiez l’effet localement.
- Activez Bot Management ou équivalent en mode détection et observez les hits marqués comme bots.
- Analysez les logs pendant 48-72 heures et ajustez une règle Firewall en mode log avant de la durcir.
Le kit d’outils éditorial et technique à activer sur votre site WordPress
Commencez par raisonner contenu par contenu : distinguez ce que vous voulez indexer, ce qui doit rester privé et ce qui peut être exploité sans risque. Le premier niveau de contrôle est éditorial et se gère dans le code du site ou via les plugins SEO.
Robots.txt : écrire des directives utiles, et connaître leurs limites
Rédigez un robots.txt clair qui bloque les chemins sensibles (par exemple /wp-admin/), autorise les ressources nécessaires et déclare vos sitemaps. Ce fichier exprime un souhait ; les crawlers respectueux s’y conforment, d’autres l’ignorent. Considérez robots.txt comme un premier garde‑fou, pas une barrière technique.
Meta robots et X‑Robots‑Tag : contrôler indexation et diffusion fine
Utilisez meta name="robots" sur les pages HTML pour appliquer noindex ou nofollow et déployez X‑Robots‑Tag au niveau HTTP pour empêcher l’indexation de fichiers non‑HTML (PDF, images). Ces signaux permettent de cibler précisément les pages d’archives, les ressources réservées aux abonnés ou tout contenu sensible sans couper l’ensemble du site du référencement.
Réglages WordPress et plugins SEO
Activez l’option de visibilité pour les moteurs si vous avez besoin d’un blocage global temporaire (Settings → Reading). Pour un contrôle fin, utilisez des plugins SEO comme Yoast ou Rank Math pour appliquer noindex, canonical, ou X‑Robots‑Tag par type de contenu. Privilégiez des règles par type de contenu plutôt que des suppressions massives qui pourraient nuire au référencement légitime.
Exemples pratiques et mise en place rapide
- Bloquez l’accès aux zones privées via robots.txt et ajoutez X‑Robots‑Tag pour les fichiers exposés.
- Marquez les pages d’archives et les flux RSS avec noindex pour limiter leur indexation.
- Contrôlez les réglages généraux de visibilité et testez les impacts SEO avant et après modification.
Ces actions combinées limitent l’indexation par les moteurs respectueux et préparent le terrain à un filtrage plus strict côté CDN/WAF. Testez chaque changement avec vos logs et outils d’analyse avant de généraliser.
Pourquoi la simple inspection du User‑Agent ne suffit pas
Le User‑Agent et les directives du robots.txt reposent sur la bonne foi : ils sont faciles à usurper et beaucoup de crawlers malveillants les ignorent. Bloquer sur la seule base d’un User‑Agent expose aussi au risque de bloquer des indexeurs légitimes ou des services partenaires qui utilisent des signatures proches. La défense efficace combine ces signaux déclaratifs avec une détection comportementale : rythme de requêtes, navigation sans chargement des ressources habituelles, absence d’exécution JavaScript. C’est cette évaluation comportementale qui permet au CDN/WAF d’appliquer des mesures actives (challenge, blocage, limitation) adaptées. En pratique, considérez les protections réseau comme la seconde ligne, à activer une fois les balises éditoriales en place.
Actionner Cloudflare et les protections réseau : règles concrètes pour limiter les collectes automatisées
Le filtrage réseau doit s’appuyer sur des règles combinant plusieurs signaux pour réduire les faux positifs. Commencez toujours en mode détection pour observer sans impacter les visiteurs. Analysez les logs pour identifier patterns et adresses récurrentes avant de passer en mode blocage ou challenge.
Configurer Bot Management
Activez Bot Management pour distinguer bots « vérifiés » de comportements automatisés suspects. Réglez la sensibilité en fonction de votre trafic : démarrez en détection, examinez les hits marqués comme bots puis définissez des actions graduées (challenge, JavaScript challenge, blocage) pour les signatures manifestement malveillantes.
Écrire des Firewall Rules opérationnelles
Créez des règles composées qui combinent taux de requêtes, en‑têtes absents (Accept, Referer), pattern d’URL ciblées (pages d’articles), pays et User‑Agent suspect. Par exemple : si une IP effectue un nombre anormal de requêtes sur vos pages d’articles en peu de temps ET n’exécute pas le JavaScript client, appliquez un challenge. Testez chaque règle en mode « Log » pour déceler faux positifs et affiner les conditions.
Limiter les abus par Rate Limiting et challenges
Définissez des limites de requêtes sur endpoints sensibles (pages articles, flux RSS). Utilisez des challenges (JavaScript challenge ou CAPTCHA) pour vérifier l’origine humaine d’une requête ou l’appartenance à un bot vérifié. Pour les ressources non publiques, combinez ces règles avec l’ajout d’en‑têtes X‑Robots‑Tag côté serveur lorsque des seuils sont dépassés.
Surveillance, logs et ajustements
Surveillez régulièrement les logs du firewall et exportez‑les pour les comparer aux access logs WordPress. Identifiez signatures répétitives, adresses IP et plages suspectes. Prévoyez des listes blanches pour indexeurs légitimes afin d’éviter de couper les services utiles. Enfin, si Cloudflare ou beehiiv publient des outils dédiés aux « AI crawlers », intégrez‑les uniquement après vérification de la documentation officielle et des tests en environnement contrôlé.
Conclusion : une démarche combinée et itérative pour protéger votre contenu
Protéger un site WordPress contre les collectes automatisées nécessite une stratégie en couches : politiques éditoriales (robots.txt, meta, X‑Robots‑Tag), configuration fine via WordPress et plugins SEO, puis filtrage actif via le CDN/WAF. Ne comptez pas sur un seul levier : testez d’abord en mode détection, examinez les logs pour identifier faux positifs, ajustez les règles et durcissez progressivement. Vérifiez toujours les documentations officielles des outils (Cloudflare, beehiiv) avant d’adopter de nouvelles fonctions. Cette démarche pragmatique réduit sensiblement les collectes indésirables tout en préservant l’accès des moteurs et services légitimes.
Points clés à retenir
- Ne vous fiez pas uniquement au robots.txt ou au User‑Agent : ces signaux sont volontaires et faciles à usurper.
- Combinez signaux éditoriaux (robots.txt, meta robots, X‑Robots‑Tag) et réglages SEO avec un filtrage réseau (Bot Management, Firewall Rules) activé en mode détection d’abord.
- Testez chaque règle via logs et outils d’analyse pour limiter les faux positifs avant de passer au blocage ou aux challenges.
Foire Aux Questions
Le robots.txt suffit‑il à empêcher les crawlers IA ?
Non. Le robots.txt exprime un souhait et est respecté par les crawlers bienveillants, mais peut être ignoré ou contourné. Il sert de premier garde‑fou, pas de barrière technique.
À quoi sert l’en‑tête X‑Robots‑Tag ?
X‑Robots‑Tag s’applique au niveau HTTP et permet d’empêcher l’indexation de ressources non‑HTML (PDF, images) ou de contrôler l’indexation fine lorsque les meta tags HTML ne sont pas suffisants.
Quand activer les règles Cloudflare ou le Bot Management ?
Commencez toujours en mode détection pour observer le comportement. Analysez les patterns dans les logs puis appliquez des actions graduées (challenge, blocage) sur les signatures manifestement malveillantes.
Quels sont les risques de bloquer sur la base du User‑Agent ?
Bloquer uniquement selon le User‑Agent accroît les faux positifs et peut couper des indexeurs légitimes ou des services partenaires, car les User‑Agent sont faciles à usurper.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Acteur majeur du web et de la recherche, souvent source des evolutions SEO et IA.
Yoast SEO
Site officielExtension WordPress de reference pour le SEO editorial, technique et structurel.
Rank Math
Site officielExtension SEO WordPress orientee optimisation technique, schema et pilotage de contenu.
Sources et Références
Pourquoi cet article
Pourquoi ce sujet ? Les flux récents montrent un signal clair : des plateformes (Cloudflare et beehiiv) proposent aux éditeurs de nouveaux contrôles pour les crawlers IA.








