

Bloquer les crawlers d’IA : ce que change l’actualité et pourquoi agir
Vous remarquez une montée de collectes massives de contenu et vous vous demandez comment protéger les articles et les bases documentaires de votre site WordPress sans couper l’accès aux lecteurs. La mise à disposition grand public de modèles de langage et les récents débats réglementaires ont rendu la récolte automatique d’autant plus stratégique : il ne s’agit plus seulement de limiter l’accès aux robots nuisibles, mais de réduire la probabilité que votre contenu soit indexé et utilisé comme corpus d’entraînement. Cet article présente un plan d’action opérationnel et pragmatique : commencer par des contrôles non intrusifs ciblant l’indexation (meta robots, X‑Robots‑Tag), compléter par des protections d’infrastructure (WAF, gestion des bots, CAPTCHAs, authentification/paywall) et formaliser un cadre juridique et de surveillance (mentions/licences, logs, playbook). L’approche vise à limiter l’extraction à grande échelle tout en préservant la visibilité publique des pages que vous souhaitez conserver dans les résultats de recherche.
Conseil pratique
Un test simple et limité permet de mesurer l'impact avant généralisation.
- Choisir un périmètre restreint (une catégorie d'articles ou un dossier média) pour tester les règles.
- Appliquer noindex via votre plugin SEO ou ajouter un X‑Robots‑Tag sur ces pages.
- Surveiller l'évolution d'accès et d'indexation (crawl interne, Search Console) et activer des règles WAF légères si nécessaire.
Mesures SEO et WordPress : empêcher l’indexation sans perdre de visibilité
Comprendre crawling vs indexation
Le crawling correspond à la lecture automatisée des pages par un robot ; l’indexation est l’inclusion de ces pages dans un index de recherche. Robots.txt permet de demander aux crawlers de ne pas visiter certaines URL, mais ce mécanisme repose sur l’adhésion volontaire des robots et ne bloque pas l’indexation si d’autres signaux existent ou si le contenu est référencé ailleurs. Pour conserver une page accessible aux visiteurs tout en évitant qu’elle soit reprise dans des corpus d’entraînement, il faut cibler l’indexation plutôt que bloquer uniquement le crawl.
Priorité : meta robots et X‑Robots‑Tag
La mesure recommandée est d’empêcher l’indexation via la balise meta robots (noindex) ou via l’en‑tête HTTP X‑Robots‑Tag. Ces signaux indiquent aux indexeurs de ne pas inclure la page dans leurs résultats tout en la laissant disponible pour les utilisateurs. Sur WordPress, ces balises se gèrent soit globalement, soit par type de contenu (articles, pages, médias) : activez noindex pour les sections que vous ne souhaitez pas voir réutilisées comme corpus d’IA et laissez index les pages destinées au référencement naturel. Après modification, utilisez Google Search Console pour vérifier l’état d’indexation et forcer une réinspection si nécessaire.
Configurer robots.txt et plugins WordPress
Conservez un fichier robots.txt pour limiter le crawl des ressources non publiques (par exemple /wp-admin/ ou certains assets), en gardant à l’esprit que bloquer des robots connus peut réduire du trafic. Sur WordPress, gérez robots.txt et les en‑têtes soit directement via le tableau de bord, soit avec des plugins SEO comme Yoast ou Rank Math. Ces outils permettent de définir noindex par type de contenu, d’ajouter X‑Robots‑Tag sur les réponses HTTP et de générer des règles pour les pages paginées ou les flux. Testez les réglages en préproduction, auditerez les changements avec un crawl interne et suivez l’évolution via Search Console avant de généraliser les règles.
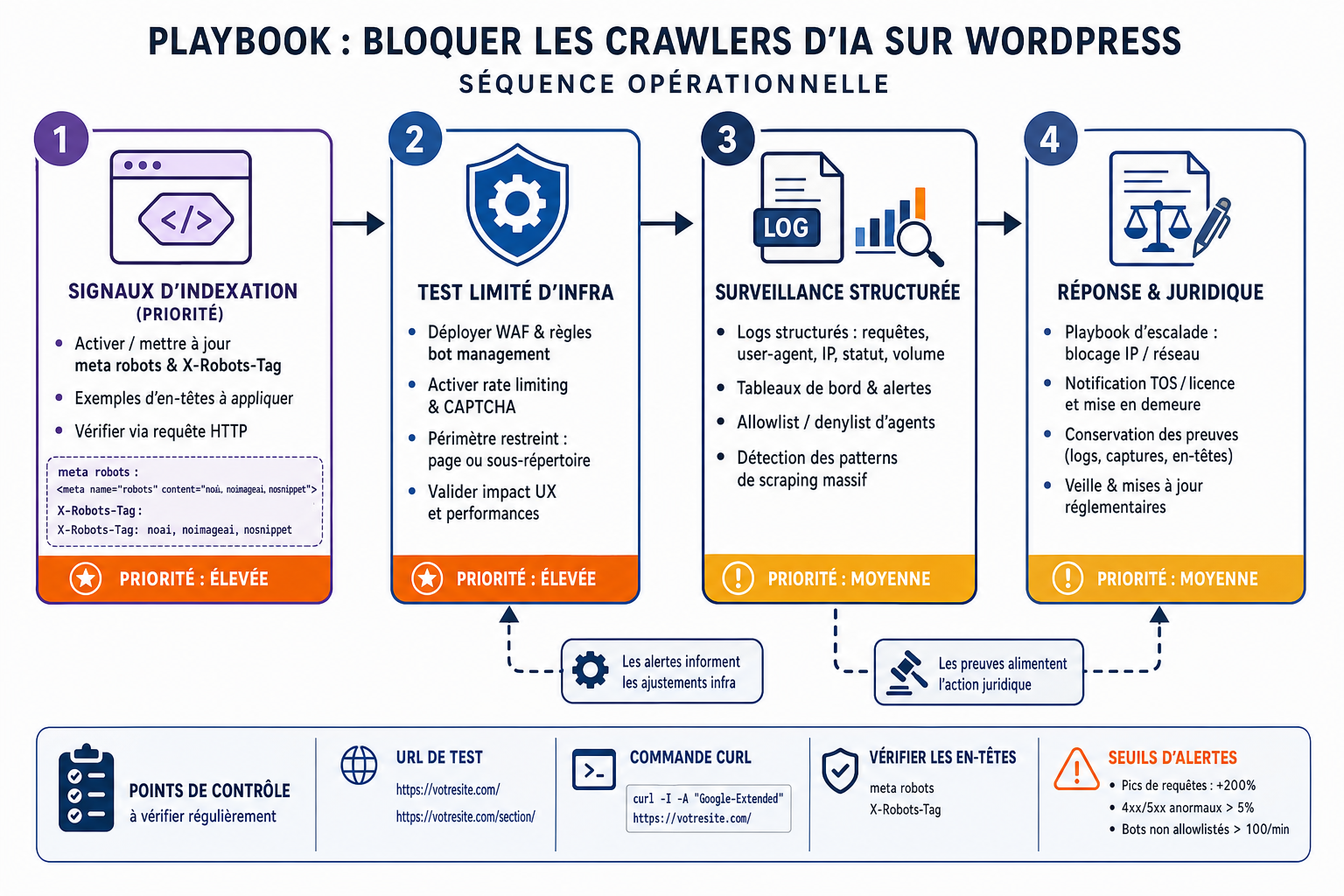
Protections d’infrastructure pour limiter la collecte automatisée
Au-delà des signaux SEO, protégez les flux serveur : déployez un WAF et une solution de bot management (par exemple Cloudflare) pour détecter et bloquer les crawlers agressifs, appliquez des règles de rate limiting et des challenges (CAPTCHA) sur les endpoints de collecte et sur les pages riches en contenu, et envisagez une authentification ou un paywall pour les contenus sensibles ou premium. Ces mesures réduisent la capacité à scraper à grande échelle mais entraînent des coûts et peuvent affecter l’expérience utilisateur et certains robots légitimes ; il faut donc évaluer l’impact SEO et la conversion sur un périmètre restreint avant généralisation.
Organisation, juridique et surveillance : formaliser une défense opérationnelle
Clauses de licence et mentions visibles
Rédigez des mentions claires indiquant l’interdiction de réutilisation massive à des fins d’entraînement sans accord explicite et proposez des licences distinctes pour l’usage humain versus l’usage machine. Ces notices s’appuient sur le droit de la propriété intellectuelle et doivent être validées par le service juridique. Intégrez aussi les risques liés aux données personnelles dans vos mentions, en tenant compte des recommandations de la CNIL citée dans le plan d’action, et prévoyez une procédure d’alerte pour les cas de scraping impliquant des données sensibles.
Logs, surveillance et règles User‑Agent
Activez la conservation structurée des logs (accès, user‑agent, rythme des requêtes, adresses IP) et mettez en place des tableaux de bord pour détecter des patterns de scraping : pics de requêtes, parcours non humains, accès répétés à des pages lourdes. Maintenez une allowlist pour les bots légitimes (moteurs de recherche connus) et une denylist dynamique pour agents malveillants. Conservez un historique suffisant pour permettre des enquêtes et, si nécessaire, des signalements aux fournisseurs d’infrastructure ou aux autorités compétentes.
Procédure opérationnelle et test
Formalisez un playbook définissant les étapes : détection, blocage temporaire, analyse technique, communication interne et décision sur l’action juridique. Testez toute règle en préproduction et planifiez des revues régulières (audit des logs, contrôle de l’impact SEO via Search Console, test des règles WAF). Coordonnez régulièrement l’équipe éditoriale, l’équipe technique et le service juridique pour décider des contenus à protéger et du niveau de protection acceptable. Cette gouvernance permet d’ajuster les protections sans nuire à la visibilité des pages publiques.
Conclusion - une stratégie combinée, graduelle et vérifiable
Protéger un site WordPress contre la collecte automatique destinée aux modèles d’IA demande une combinaison de mesures simples et vérifiables : privilégier d’abord les signaux qui empêchent l’indexation (meta robots, X‑Robots‑Tag), compléter par des protections serveur adaptées (WAF, gestion des bots, CAPTCHA, authentification) et formaliser un cadre juridique et de surveillance (mentions/licences, logs, playbook). Avancez par étapes : testez en préproduction, mesurez l’impact sur l’indexation via Google Search Console et via des crawls internes, puis ajustez. Cette approche graduelle limite les risques d’extraction massive tout en préservant la visibilité des pages destinées au public.
Points clés à retenir
- Prioriser les signaux d'indexation (meta robots, X‑Robots‑Tag) pour empêcher l'inclusion des pages dans des corpus d'entraînement tout en laissant l'accès public.
- Compléter par des protections d'infrastructure (WAF, gestion des bots, rate limiting, CAPTCHA, authentification/paywall) testées sur un périmètre restreint.
- Formaliser un cadre de surveillance et juridique : logs structurés, allowlist/denylist d’agents, mentions/licences et playbook opérationnel pour détecter et répondre au scraping massif.
Foire Aux Questions
Quelle différence entre bloquer le crawl et empêcher l'indexation ?
Le crawl désigne la lecture automatique des pages ; l'indexation est l'inclusion dans un index de recherche. Robots.txt demande aux robots de ne pas visiter, mais n'empêche pas forcément l'indexation. Pour réduire la reprise dans des corpus d'IA, ciblez l'indexation (noindex, X‑Robots‑Tag).
Appliquer noindex signifie-t-il perdre tout trafic organique ?
Noindex empêche l'inclusion d'une page dans les résultats d'un index. Conservez l'indexation pour les pages que vous souhaitez référencer ; appliquez noindex uniquement aux sections à protéger.
Les protections serveur comme WAF ou CAPTCHA peuvent-elles nuire au SEO ?
Ces protections réduisent le scraping massif mais peuvent affecter l'expérience utilisateur et certains robots légitimes. Le document recommande de tester l'impact sur un périmètre restreint avant généralisation.
Quelles informations loguer pour détecter le scraping ?
Conserver des logs d'accès structurés : user‑agent, rythme des requêtes, adresses IP et endpoints sollicités. Utiliser des tableaux de bord pour repérer pics, parcours non humains et accès répétés à pages lourdes.
Les mentions légales suffisent-elles pour empêcher la réutilisation à des fins d'entraînement ?
Des mentions et licences claires formalisent l'interdiction, mais doivent être validées par le service juridique et s'accompagner de mesures techniques et de surveillance pour être efficaces.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Acteur majeur du web et de la recherche, souvent source des evolutions SEO et IA.
Yoast SEO
Site officielExtension WordPress de reference pour le SEO editorial, technique et structurel.
Rank Math
Site officielExtension SEO WordPress orientee optimisation technique, schema et pilotage de contenu.
Claude
Site officielAssistant IA d Anthropic utilise pour redaction, analyse et automatisation de taches complexes.
CNIL
Site officielAutorite francaise de reference pour la protection des donnees personnelles et la conformite.
Sources et Références
- robots.txt specifications - Google Developers
- Control crawling and indexing - meta robots & X-Robots-Tag - Google Developers
- Documentation WordPress - How to edit robots.txt and manage headers
- Yoast - Guide sur les balises meta robots et gestion SEO (FR)
- Bot Management et protection contre le scraping - Cloudflare (documentation produit)
- CNIL - Le scraping et les données personnelles (page d'information)
- Claude Fable 5 : la puissance de Mythos accessible au grand public, avec des garde-fous - ZDNet France (signal d'actualité)
- Mesure exceptionnelle de Bruxelles, qui impose à Meta de rouvrir WhatsApp aux IA concurrentes - Next.ink (signal réglementaire/actualité)
- Brouillon : Bloquer les crawlers d’IA - plan d’action WordPress
Pourquoi cet article
Signal récent : plusieurs médias et éditeurs demandent des restrictions ou des compensations face aux collectes par IA (Search Engine Journal : « More News Sites Default To Blocking AI Crawlers », demande des éditeurs américains contre Common Crawl ; ZDNet...








