

Agents IA locaux et « physical AI » : ce qui change pour votre site WordPress
Les interactions automatisées pilotées par des agents locaux et les usages « physical AI » deviennent une réalité opérationnelle pour les sites WordPress : annonces autour de Copilot, filtres de confidentialité comme « Privacy Filter » d’OpenAI, progrès matériels cités (ex. DLSS 4.5 chez Nvidia) et évolutions backend (ex. Symfony) montrent que les assistants côté utilisateur, la recherche visuelle et le traitement vidéo en temps réel gagnent en pertinence. Pour un site, cela se traduit par trois enjeux concrets : visibilité différente (les agents citent des extraits plutôt que de diriger vers une page), nouvelles sources de revenus (offres accessibles par API pour assistants) et un besoin renforcé de contrôle des données (anonymisation, rétention, traçabilité). Cet article propose cinq actions opérationnelles et directement implémentables pour préparer votre WordPress : optimiser l’accès agent‑friendly, créer des offres monétisables, maîtriser les données, organiser l’inférence sous contrôle et adapter les pipelines visuels.
Conseil pratique
Un POC simple pour valider visibilité et demande sans gros investissement technique.
- Choisir une page à forte valeur (guide, fiche produit ou tutoriel) comme cible du test.
- Ajouter une balise JSON‑LD ou un champ 'summary' court et vérifiable pour cette page.
- Créer un endpoint REST minimal qui renvoie ce résumé en JSON et le protéger par une clé API et quotas simples.
- Appeler l’endpoint depuis un client (test interne) et vérifier que la réponse est courte, structurée et citée proprement.
Action 1-3 : préparer la visibilité agent‑friendly, créer des offres monétisables et renforcer la confidentialité
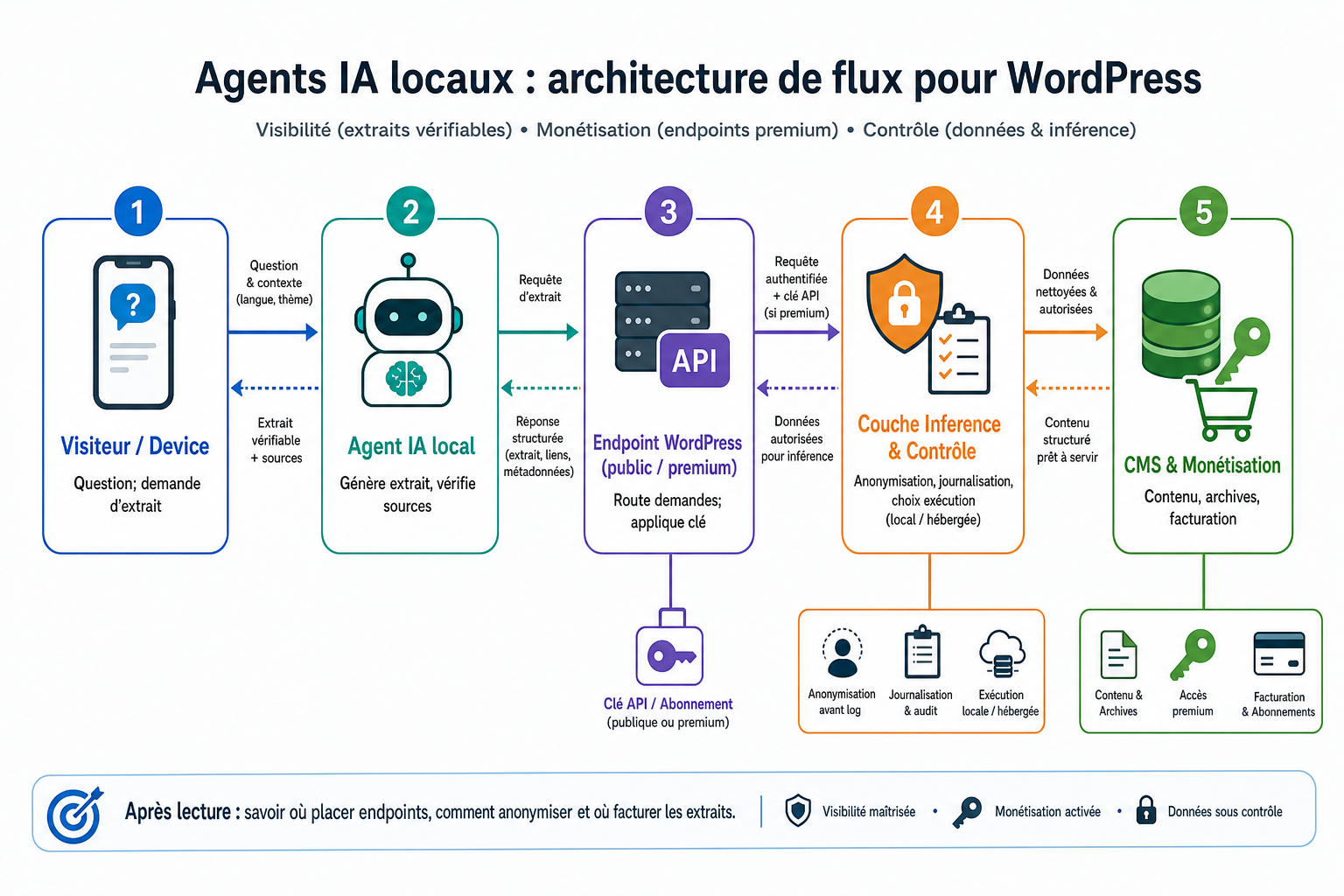
Action 1 - Optimiser l’accès des agents : structurer le contenu et exposer des points d’entrée
Rendre vos pages lisibles par des assistants locaux passe par une structuration sémantique plus stricte. Commencez par appliquer balises HTML claires pour titres et listes et ajouter des données structurées JSON‑LD pour les entités pertinentes (produits, événements). Normalisez des métadonnées courtes utiles aux agents (summary, intent tags) et créez des pages ciblées par intent : résumés, FAQ actionnables, tutoriels étape par étape. Exposez ensuite des points d’entrée machine lisibles : un endpoint REST ou GraphQL documenté qui retourne du JSON filtré, avec des champs pensés pour être cités (extraits, chapitres, timecodes). L’objectif est simple : fournir des réponses courtes et vérifiables que l’assistant pourra délivrer sans reconstruire votre page.
Action 2 - Concevoir des offres payantes pour assistants
Les assistants vont consommer des services que vos pages statiques ne monétisent pas encore. Définissez des produits adressables par API : résumés premium, accès aux archives, contenus enrichis structurés pour assistants (fiches techniques, bundles téléchargeables). Implémentez un modèle d’accès par jeton ou abonnement adapté aux usages machine : clé API, quotas et tarifs explicites. Sur WordPress, prévoyez des endpoints qui retournent un JSON propre aux agents et un mécanisme d’authentification léger (clé + limitation de débit). Anticipez aussi des déclencheurs transactionnels initiés par un assistant (réservation, achat rapide) et veillez à la traçabilité des actions facturées pour pouvoir lier consommation et facturation.
Action 3 - Maîtriser les données et appliquer le filtrage/anonymisation
La montée des filtres de confidentialité impose de réduire et d’anonymiser les informations personnelles exposées aux agents. Intégrez dès la collecte un niveau d’anonymisation : masquage des adresses e‑mail, hachage des identifiants, ou tout autre traitement qui limite l’identification directe. Conservez des journaux d’accès agrégés plutôt que traces nominatives et limitez les durées de conservation. Exigez un consentement explicite pour tout usage en machine‑learning et fournissez une interface simple pour la suppression de données utilisateur. Appliquez le principe du besoin‑de‑savoir : seules les données nécessaires à la réponse d’un agent doivent être exposées via API, et toute exposition doit être journalisée pour audit.
Checklist rapide et priorités opérationnelles pour démarrer
Priorisez des actions courtes et mesurables : 1) Audit express (2 heures) : recensez les pages les plus sollicitées par les agents, les endpoints existants et les types de médias présents ; 2) Structuration minimale (1-3 jours) : ajoutez JSON‑LD pour une dizaine de pages à forte valeur et mettez en place un endpoint de résumé simple ; 3) Politique de logs (1 jour) : activez l’anonymisation, définissez une rétention adaptée et limitez les journaux conservés (référence de rétention fournie plus haut) ; 4) Offre payante minimale (POC 1-2 semaines) : créez un produit API accessible par clé avec quota et pricing simple pour tester la demande ; 5) Test device/visual (1-2 semaines) : validez l’upload vidéo, la génération de miniatures et l’extraction de chapitres via un outil IA. L’idée : commencer par gains visibles (meilleure visibilité par agents, revenus directs) puis stabiliser l’architecture et l’hébergement au fur et à mesure.
Action 4-5 : contrôler l’exécution locale des modèles et préparer la dimension visuelle/physique
Action 4 - Héberger et orchestrer inference locale pour garder le contrôle
Décidez où les modèles doivent s’exécuter et qui contrôle les données. Vous pouvez encourager l’exécution côté client (on‑device) ou offrir des services d’inférence hébergés sous votre contrôle. Pour maîtriser les flux, préparez une architecture de micro‑services : un point d’entrée REST/GraphQL public, un moteur d’inférence séparé, un service d’authentification des clés et un service d’anonymisation avant stockage. Ajoutez journalisation chiffrée et quotas par client pour limiter l’usage et permettre le suivi. Documentez clairement les règles de rétention et fournissez un processus d’audit pour chaque requête traitée par un modèle afin de répondre aux exigences de traçabilité et de conformité interne.
Action 5 - Préparer le site aux usages visuels et « physical AI »
Les traitements visuels et les données device exigent des pipelines robustes. Automatisez le transcoding multi‑résolution, l’extraction de miniatures et de chapitres, la génération de sous‑titres et de résumés, ainsi que la production de métadonnées visuelles (scènes, objets) destinées à la recherche par image. Exposez ces éléments via API pour que les agents locaux puissent interroger des images ou des segments vidéo et fournir des réponses enrichies. Mettez en place des workflows d’ingestion prenant en charge l’upload via mobile ou WebRTC, un traitement asynchrone et une indexation dédiée. Vérifiez la qualité des extractions et offrez un mécanisme d’édition humaine pour corriger les erreurs de reconnaissance. Enfin, prévoyez des accords explicites lorsque vous combinez données issues de devices (ex. drones, caméras) et traitements IA afin de protéger les personnes filmées et clarifier les responsabilités.
Conclusion
Préparer un site WordPress à l’arrivée d’agents IA locaux et d’usages « physical AI » est d’abord une démarche pragmatique : structurez le contenu pour être cité, exposez des endpoints monétisables, anonymisez les données, organisez l’inférence sous contrôle et adaptez vos pipelines visuels. Avancez par itérations courtes : un audit rapide, puis trois POC (résumés API, clé d’accès payante, pipeline vidéo basique) suffisent pour valider les hypothèses et dégager des revenus initiaux tout en maîtrisant les risques. En priorisant visibilité agent, offre payante minimale et conformité des logs, vous transformez une contrainte technique et réglementaire en avantage concurrentiel opérationnel.
Points clés à retenir
- La visibilité change : les agents donnent des extraits vérifiables plutôt que d’amener systématiquement vers une page complète.
- La monétisation peut passer par des endpoints API dédiés (résumés premium, accès aux archives, offres accessibles par clé).
- Le contrôle des données et de l’inférence (anonymisation, journalisation, exécution locale ou hébergée) devient central, en particulier pour les flux visuels et device.
Foire Aux Questions
Quel est le premier test à réaliser pour vérifier l’intérêt des agents IA ?
Réalisez un POC sur une page à forte valeur : exposez un résumé JSON‑LD et un endpoint /api/summary protégé par clé. Vérifiez que la réponse est exploitable pour un assistant et qu’elle suscite des requêtes.
Comment monétiser l’accès des assistants sans restructurer tout le site ?
Créez des produits API ciblés (résumés premium, accès aux archives) accessibles par clé et quotas. Commencez par un petit POC avec pricing simple et journalisation pour lier consommation et facturation.
Quelles mesures de confidentialité appliquer avant d’exposer des données aux agents ?
Appliquez un masquage/anonymisation à la collecte, limitez la conservation des journaux à des traces agrégées et exigez un consentement explicite pour les usages de machine‑learning. Exposez via API seulement les données nécessaires à la réponse.
Faut‑il exécuter les modèles localement (on‑device) ou héberger l’inférence ?
Les deux options existent. L’exécution locale réduit l’exfiltration de données, tandis que l’inférence hébergée permet un contrôle centralisé. Préparez une architecture qui sépare point d’entrée, moteur d’inférence et anonymisation, et documentez les règles de rétention.
Comment préparer les contenus visuels pour les usages « physical AI » ?
Automatisez le transcoding multi‑résolution, l’extraction de miniatures et de chapitres, la génération de sous‑titres et de métadonnées visuelles, exposez ces éléments via API et gardez une édition humaine pour corriger les erreurs de reconnaissance.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Perplexity AI
Site officielMoteur de recherche conversationnel base sur l IA, centre sur les reponses syntheses.
Microsoft Copilot
Site officielAssistant IA de Microsoft integre aux usages bureautiques, recherche et developpement.
OpenAI
Site officielEntreprise a l origine de modeles generatifs utilises pour redaction, code et assistants IA.
Sources et Références
- ☕️ Microsoft voudrait ranger tous ses Copilot dans une app unique
- OpenAI Privacy Filter : masquer les données personnelles
- Nvidia corrige enfin le plus gros défaut visuel du Ray Tracing avec le DLSS 4.5
- Pour faire des vlog cet été, la DJI Pocket 3 à 50% du prix s’écoule par palettes entières
- Symfony 8.1 : améliorations diverses sur la console, les dépendances, JSON
Pourquoi cet article
Pourquoi ce sujet maintenant : plusieurs annonces récentes pointent vers une évolution concrète - modèles et agents capables de raisonner et d’agir localement (NVIDIA Cosmos 3, déploiement d’agents locaux sur RTX/DGX ; Hugging Face) tandis que des tensions...








