

Granite R2 et l’onde de choc des embeddings multilingues open‑source
Un nouveau paysage technique se dessine avec l’arrivée d’embeddings multilingues disponibles sur des hubs open‑source comme Hugging Face. Pour un site WordPress ou une agence, cela signifie que la recherche sémantique performante n’exige plus systématiquement le recours à des API payantes : on peut héberger en interne un modèle téléchargeable, contrôler ses données et réduire certains coûts récurrents. Cette évolution change aussi la manière de penser le contenu : le retrieval cross‑lingue rend pertinent de regrouper les pages par intention utilisateur plutôt que par simple traduction. Enfin, elle impose des décisions concrètes - choix de modèle, vérification de licences, dimensionnement d’infrastructure et maintenance logicielle - qui pèsent sur la faisabilité. Cet article propose un plan d’action opérationnel pour vérifier, piloter et industrialiser ces acquis sur un site WordPress, sans s’appuyer sur des présupposés techniques non vérifiés.
Conseil pratique
Trois étapes concrètes pour valider l'intérêt technique et éditorial sans engager l'infra complète.
- Consultez la fiche modèle sur Hugging Face pour vérifier licence et prérequis techniques.
- Téléchargez un modèle d'embeddings compact et lancez l'inférence sur un échantillon de 200-500 phrases représentatives du site.
- Indexez ces vecteurs dans une base vectorielle locale, connectez-la au front WordPress et testez la pertinence avec une vingtaine de requêtes réelles.
Impacts opérationnels détaillés et décisions à prendre
1. Héberger la recherche sémantique en interne : avantages et contraintes
Héberger un modèle d’embeddings téléchargeable apporte plusieurs gains : baisse des coûts d’API à l’usage, maîtrise des données sensibles, latence contrôlée et indépendance vis‑à‑vis d’un fournisseur externe. En contrepartie, il faut confirmer que le modèle est téléchargeable et compatible avec votre infrastructure, estimer les besoins CPU/GPU, prévoir le stockage pour l’index vectoriel et organiser la maintenance logicielle. Actions concrètes immédiates : consulter la fiche modèle sur Hugging Face pour licence, poids et instructions d’inférence ; tester localement un modèle compact (par exemple des familles MiniLM évoquées dans l’écosystème SentenceTransformers) ; mesurer la latence sur l’infrastructure cible ; et estimer le coût total de possession en incluant équipes, monitoring et mises à jour.
2. Stratégie de contenu multilingue fondée sur l’intention
Les embeddings multilingues permettent d’identifier intents et entités au‑delà des langues, ce qui invite à restructurer l’offre de contenu. Plutôt que de multiplier des traductions mot à mot, il devient pertinent de concevoir des pages piliers et des FAQ centrées sur des intentions universelles, puis de localiser ou d’enrichir ces pages selon les marchés. Concrètement, on peut créer des clusters sémantiques multilingues pour la navigation et la recommandation, utiliser le retrieval cross‑lingue pour alimenter les suggestions sans dupliquer le contenu, et prioriser la création sur les intents à fort impact. Mesures à suivre pour valider la stratégie : taux de clics sur les résultats sémantiques, réduction des doublons de contenu et couverture d’intents par langue.
3. SEO, expérience utilisateur et analytics
Sur le plan SEO et UX, l’adoption d’embeddings multilingues vise d’abord à améliorer la pertinence des résultats internes et des recommandations, ce qui devrait augmenter le temps de session et les conversions lorsque les réponses sont pertinentes. Il faut cependant rester vigilant : les manipulations sémantiques ne doivent pas dégrader les signaux indexables par les moteurs externes, notamment via une gestion cohérente des sitemaps et des balises hreflang. Intégrez des métriques UX spécifiques au suivi : taux de rebond après recherche, conversions issues de la recherche interne et satisfaction éditoriale. Ces indicateurs permettront de lier la valeur métier aux choix techniques.
4. Licences, maintenance et risques juridiques
Choisir un modèle open‑source réduit la dépendance commerciale mais n’élimine pas les obligations légales. Chaque modèle a sa licence propre : il est indispensable de vérifier la fiche modèle avant tout déploiement commercial. La maintenance, les mises à jour et la sécurité des instances sont à la charge de l’organisation, et le fine‑tuning ou la redistribution peuvent être soumis à des restrictions contractuelles. Checklist immédiate à formaliser : validation de la licence commerciale, définition d’une politique de rétention des données d’indexation et planification d’une revue légale avant mise en production.
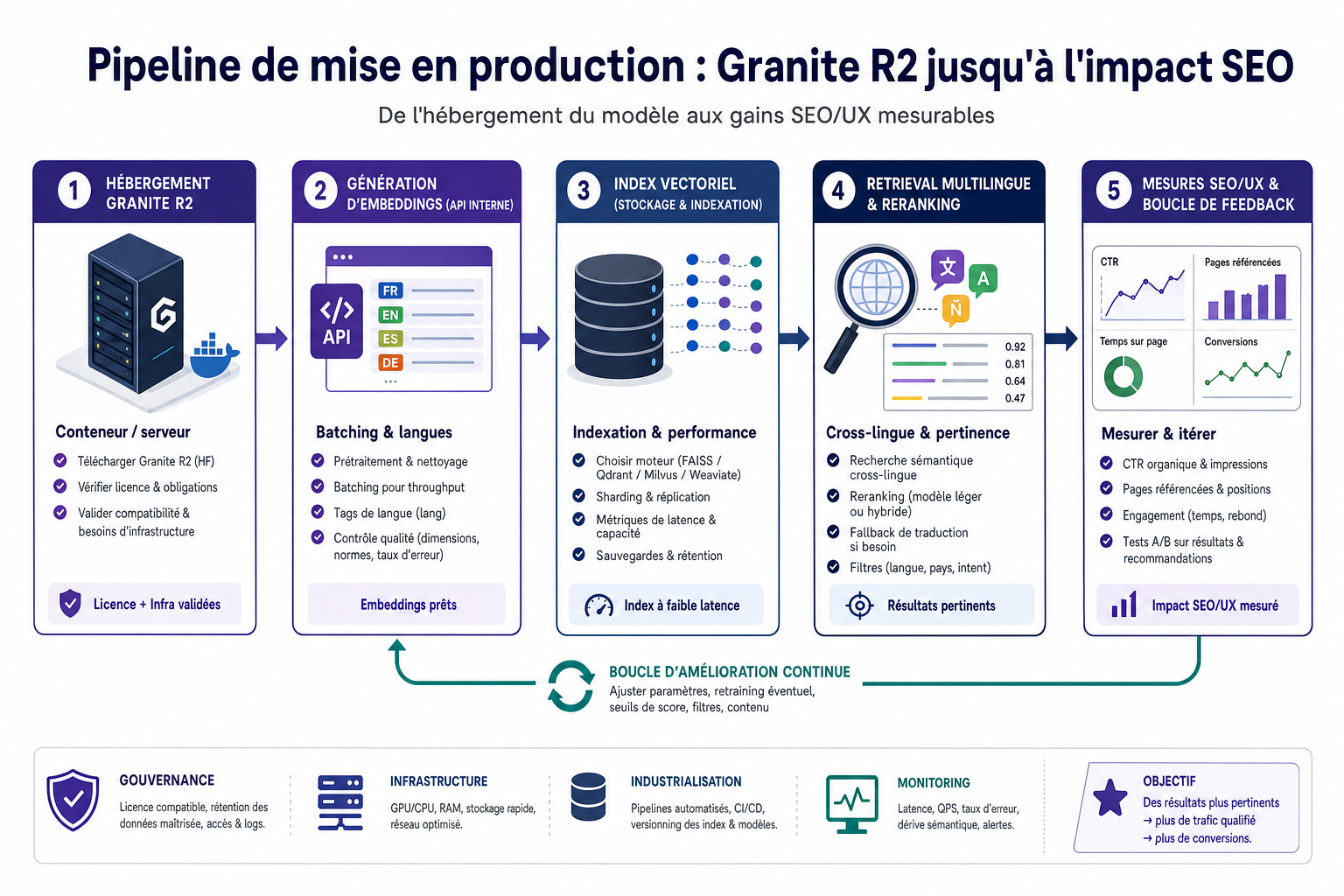
Bloc « démarrage rapide » : comment lancer un pilote en une matinée
Consultez d’abord la fiche modèle sur Hugging Face pour confirmer licence et prérequis ; clonez ensuite un modèle d’embeddings compact (par exemple une variante MiniLM ou un équivalent multilingue) et lancez l’inférence sur un échantillon de 200-500 phrases représentatives de votre site ; indexez ces vecteurs dans une base vectorielle locale ou un service open‑source ; connectez la recherche par similarité au front WordPress via un plugin ou un microservice simple ; testez la pertinence avec une vingtaine de requêtes réelles et recueillez le retour éditorial immédiat ; enfin, décidez d’un périmètre pilote (catalogue produit, FAQ ou blog) et documentez rapidement les coûts d’infrastructure estimés pour décider d’un passage à l’étape suivante.
Feuille de route opérationnelle : du pilote à la production
Phase 0 - Validation et gouvernance
Avant toute expérimentation, vérifiez la licence et la compatibilité technique du modèle choisi, définissez le périmètre initial (sections du site) et nommez un responsable technique et un référent éditorial. Produisez une fiche de conformité licence, un cahier des intents prioritaires et un plan de test minimal. KPI initiaux à mesurer : temps de réponse d’inférence en local et pourcentage d’intents couverts par votre dataset de test.
Phase 1 - Prototype sur un périmètre restreint
Pour le prototype, déployez le modèle d’embeddings sur une machine dédiée ou un container, indexez un sous‑ensemble représentatif du contenu et branchez la recherche vectorielle au front WordPress via API ou plugin. Si vous ne disposez pas de GPU, privilégiez un modèle compact pour CPU ; sinon une instance GPU réduit la latence. Collectez des retours utilisateurs pour mesurer la pertinence, suivez la latence moyenne et estimez le coût opérationnel initial.
Phase 2 - Industrialisation technique
Passer en production implique de choisir une base vectorielle adaptée à la scalabilité et aux fonctionnalités attendues (clustering, filtres, persistance), de mettre en place des pipelines d’indexation automatisés et incrémentaux, et d’intégrer monitoring et alerting. Formalisez une politique de refresh des embeddings, maintenez un versioning des modèles et prévoyez une stratégie de sauvegarde des index. Impliquez DevOps pour l’infra, un développeur WordPress pour l’intégration et l’équipe éditoriale pour la supervision sémantique.
Phase 3 - Transformation éditoriale
À l’échelle, cartographiez les intents prioritaires par marché et langue, restructurez les silos en clusters sémantiques, définissez des règles claires de localisation versus création originale, et produisez des templates de pages centrés sur l’intent. Mesurez la valeur métier avec des indicateurs tels que la variation du trafic organique par cluster, l’évolution des conversions issues de la recherche interne et le nombre de traductions évitées grâce au retrieval cross‑lingue.
Phase 4 - Maintenance et évolution
Installez une routine de revue de performance du modèle, planifiez des tests A/B lors de tout changement de modèle, organisez un audit annuel de licence et de conformité, et formalisez un plan de mise à jour incluant la possibilité de fine‑tuning si nécessaire. Prévoyez un budget récurrent pour l’infrastructure et l’expertise, et une procédure de rollback en cas de régression après une mise à jour.
Conclusion : décider et passer à l’action
Pour un site WordPress ou une agence, les embeddings multilingues open‑source représentent une opportunité pragmatique : il est possible de tester rapidement en local, de mesurer des gains UX et SEO, puis de choisir entre internalisation complète ou approche hybride. Priorisez un pilote court sur un périmètre critique, validez la licence sur la fiche modèle avant tout déploiement commercial et alignez la production de contenu sur les intents identifiés plutôt que sur une traduction mécanique. Si le pilote confirme des bénéfices mesurables, engagez l’industrialisation en gardant une gouvernance claire sur la maintenance, le versioning et la conformité.
Points clés à retenir
- Héberger un modèle d'embeddings téléchargeable permet de réduire la dépendance aux API payantes, de mieux contrôler les données et d'agir sur la latence, mais exige de vérifier licence, compatibilité et besoins d'infrastructure.
- Les embeddings multilingues rendent pertinent un focus éditorial par intention utilisateur : clusters sémantiques et retrieval cross‑lingue peuvent réduire les traductions mot à mot et améliorer les recommandations.
- La mise en production demande une gouvernance claire (licence, data retention), une industrialisation technique (index vectoriel, pipelines, monitoring) et des métriques SEO/UX pour mesurer la valeur métier.
Foire Aux Questions
Comment vérifier que je peux utiliser un modèle open‑source pour un déploiement commercial ?
Consultez la fiche modèle sur la plateforme qui l'héberge pour lire la licence associée. Formalisez une fiche de conformité avant tout déploiement commercial et, si nécessaire, soumettez la licence à une revue juridique interne.
Quels sont les besoins d'infrastructure à anticiper ?
Il faut estimer si le modèle peut tourner efficacement sur CPU ou s'il nécessite un GPU, prévoir le stockage pour l'index vectoriel et dimensionner monitoring et pipelines d'indexation. Mesurez la latence sur une infrastructure cible avant industrialisation.
L'utilisation d'embeddings multilingues risque‑t‑elle d'affecter le SEO externe ?
Le principal risque vient d'une mauvaise gestion des versions indexables du contenu. Conservez une gestion claire des sitemaps et des balises hreflang, et suivez des métriques indexables (trafic organique par cluster) pour vérifier l'impact.
Faut‑il internaliser totalement la solution ou privilégier une approche hybride ?
Le choix dépend des priorités : internalisation = plus de contrôle et potentiellement moins de coûts récurrents, mais demande maintenance et expertise. L'approche hybride peut réduire l'effort initial tout en testant la valeur avant d'internaliser.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Acteur majeur du web et de la recherche, souvent source des evolutions SEO et IA.
Pourquoi cet article
Angle éditorial précis et actionnable centré sur un signal récent et structurant : Hugging Face a publié Granite Embedding Multilingual R2, un jeu d'embeddings open‑source (licence Apache 2.0) avec contexte 32K et « meilleure qualité de recherche » parmi les...








